LiveCodeBench & LiveCodeBench Pro
LiveCodeBench -> LiveCodeBench Pro, reviewing one of the most classic benchmark. (PS:The cover is generated by AI -- I found LLM -> html -> graph is better than VGen Model..)

LiveCodeBench & LiveCodeBench Pro
LCB
Background
已有的 Code Bench 主要面临两个问题:数据污染,评估维度单一。
Method
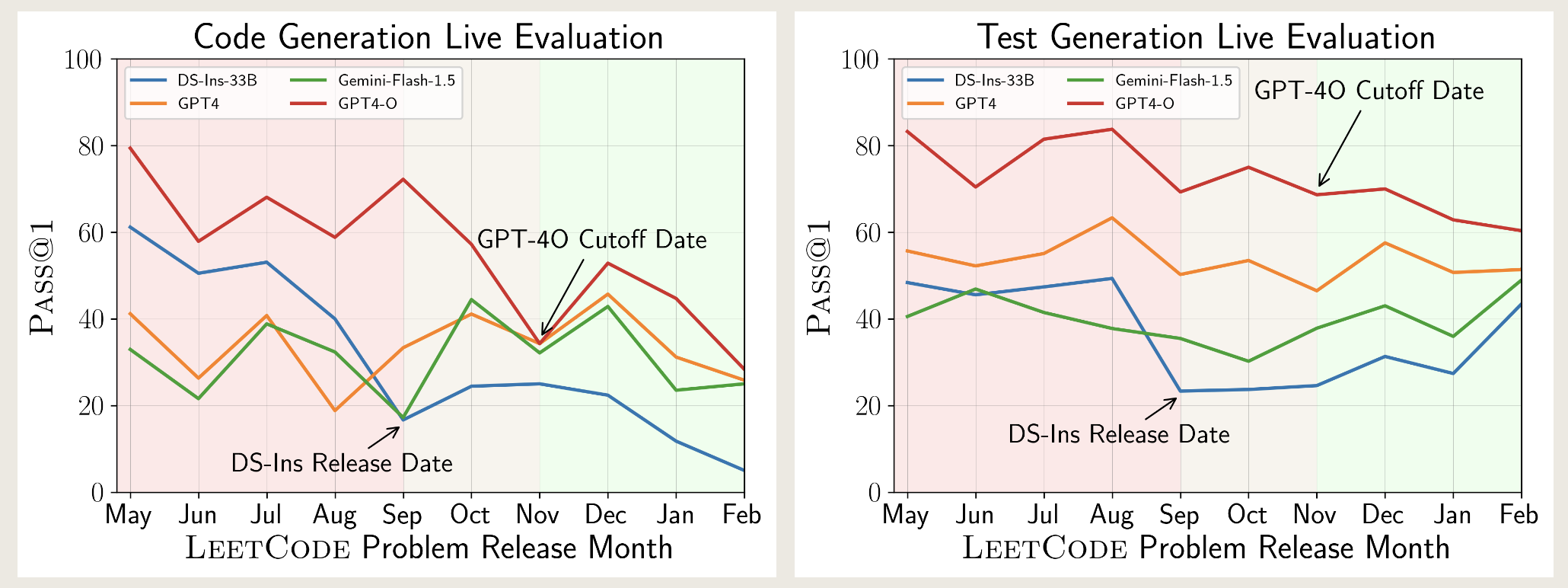
Live评估
- 从三大编程竞赛平台(LeetCode, AtCoder, CodeForces)收集最新的竞赛题目来构建测试集。
- 根据模型的时间截止日期(Cutoff Date)进行评估。
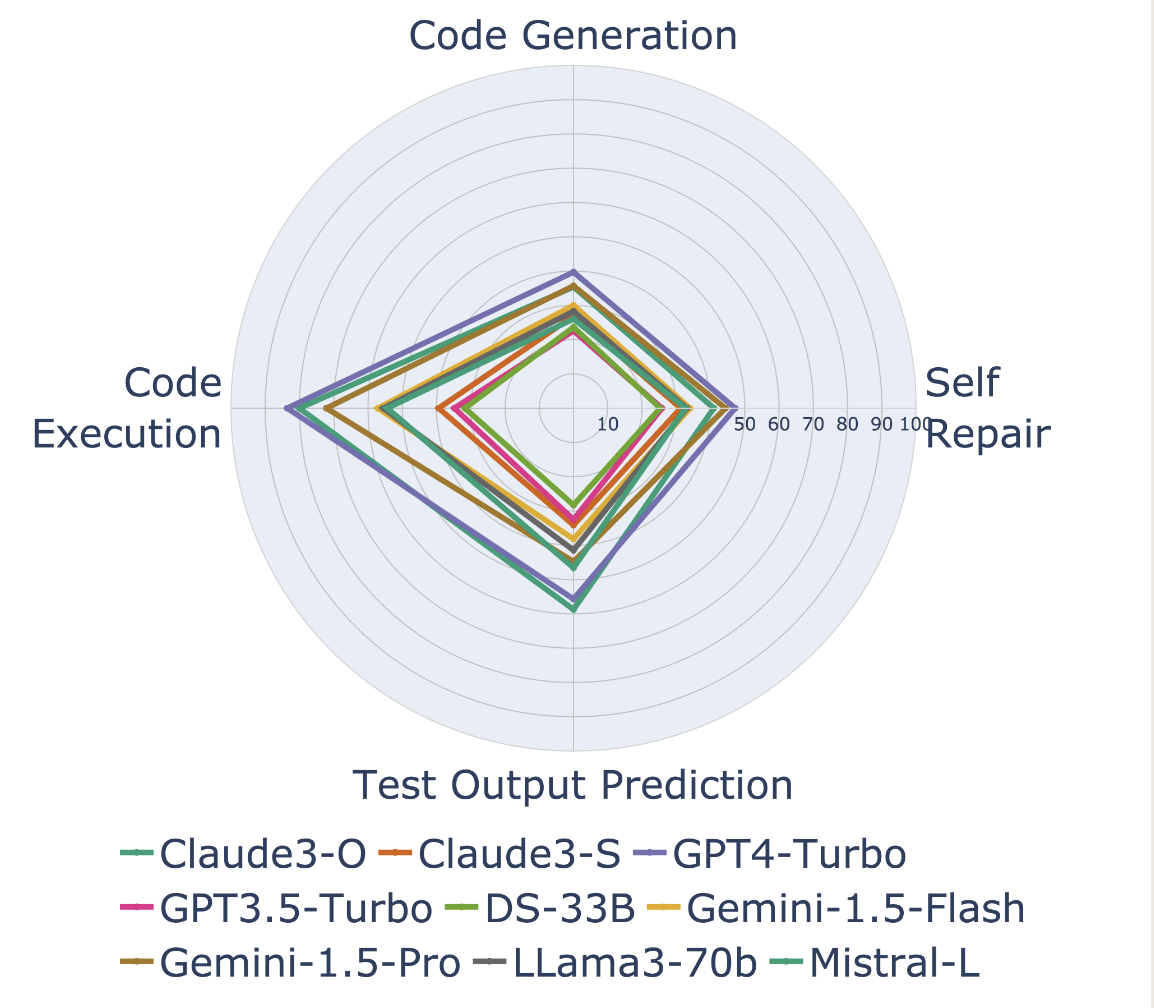
Holistic
- 代码生成 (Code Generation): 根据自然语言描述生成代码(标准任务)。
- 自我修复 (Self-Repair): 给定错误的代码和报错信息(或失败的测试用例),让模型修复代码。
- 代码执行 (Code Execution): 给定代码预测 Sample 结果。
- 测试输出预测 (Test Output Prediction): 纯自然语言预测 Sample 结果。
Data
- 每道题 17 个 Sample - 很好奇 SPJ 之类的,个人认为可以使用对拍,不止这么多数据。
- 难度分级:易/中/难
Contribution
最核心的就是难以作弊,排除了过拟合的问题。其真实的代码能力不就是一个逻辑链么,反正就是大家都在做的…分析题目,给出逻辑推理的过程,运用合理的算法(也许需要微调),然后最后做出来。然后发现的能力维度区别,应该是模型训练的时候数据带来的影响。
大模拟,数据超大,SPJ?
现在这个Bench的能力早已饱和,我们来看 LCBP。
LCBP
Background
近期研究宣称,大型语言模型在竞技编程领域已超越人类顶尖选手。为了验证这个,专门收集了难题来测LLM,包括IOI。(人类在IOI是可以拿满分的)
Method
发现LCB也有数据污染。为此构造更加严苛的数据集。剔除了 LeetCode。保持了 Live 的特性。
专家标注
 由奥赛金牌得主团队对每个问题进行详细标注,不仅标注了算法标签(如动态规划、图论),还引入了认知侧重分类(Cognitive-focus Taxonomy)。(感觉跟洛谷这样的现有社区是一样的,不过不知道用这些数据侵不侵权。) 为啥线段树不算数据结构?
由奥赛金牌得主团队对每个问题进行详细标注,不仅标注了算法标签(如动态规划、图论),还引入了认知侧重分类(Cognitive-focus Taxonomy)。(感觉跟洛谷这样的现有社区是一样的,不过不知道用这些数据侵不侵权。) 为啥线段树不算数据结构?
- 知识密集型 (Knowledge-heavy): 依赖已知模板或算法(如线段树)。
- 逻辑密集型 (Logic-heavy): 依赖按部就班的数学推导(如组合数学)。
- 观察密集型 (Observation-heavy): 依赖“灵光一现”的洞察力或思维跳跃(如贪心算法、构造题)。
更换评估指标
贝叶斯 Elo 评分 (Bayesian Elo Rating):使其能直接与人类选手(如 Codeforces 积分)进行对比 。
结论
- 模型与人类差距仍大。
- 知识、逻辑表现较好,观察型不行。
- 推理模型可以提升逻辑。
- 错误大多集中在算法本身,如图。(与近似分数的人类做对比)而且样例没过的有很多,因为是Pass@1.´

- 工具使用会显著提高 Elo分数,但本身就带有欺骗性,如Pass@k。OpenAI的2700可能要削弱400分才行。
个人认为,Coding 可以进行 pass@k 自我修复一些问题。有人做这样的bench吗?
本文由作者按照 CC BY 4.0 进行授权