SR-Eval
SR-Eval, A powerful benchmark focus on multi-turn optimization and multi agent generating and reviewing.

SR-Eval
这篇文章有着不错的话题,但是论文排版有很多细节错误,有些地方比较拗口,结构绘图都可以提升,我认为可以继续打磨。
背景
基准测试中,任务多为静态单轮问题,忽略了软件开发中的多轮迭代过程。 实践中,开发者很少基于完整需求进行开发,而是通过连续的开发迭代逐步完善需求,动态调整解决方案。 没有足够的真实开发交互数据,多轮之间的语义对齐也是问题。
模型局限性
- SOTA 模型还是很菜,reasoning并不会带来提升,而prompt策略才能更好平衡模型的能力和效率
Related Works
有很多人比如SWE做过了仓库级别的Bench,也有很多人做了func级别的Code Bench,但是他们规模不够大。
SR-Eval
涵盖函数级与仓库级编程任务,支持Python和Java语言,共包含314个函数级任务(含1,348次指令交互)及129个仓库级任务(含509次指令交互)。
采用多智能体需求生成方法模拟真实迭代开发场景,将完整需求转化为多轮演进式指令;继而提出语义感知的判别性测试用例生成方案,为每轮交互合成具有判别力的测试用例,既确保正确性验证,又精准契合每轮迭代的增量需求特性。
Method
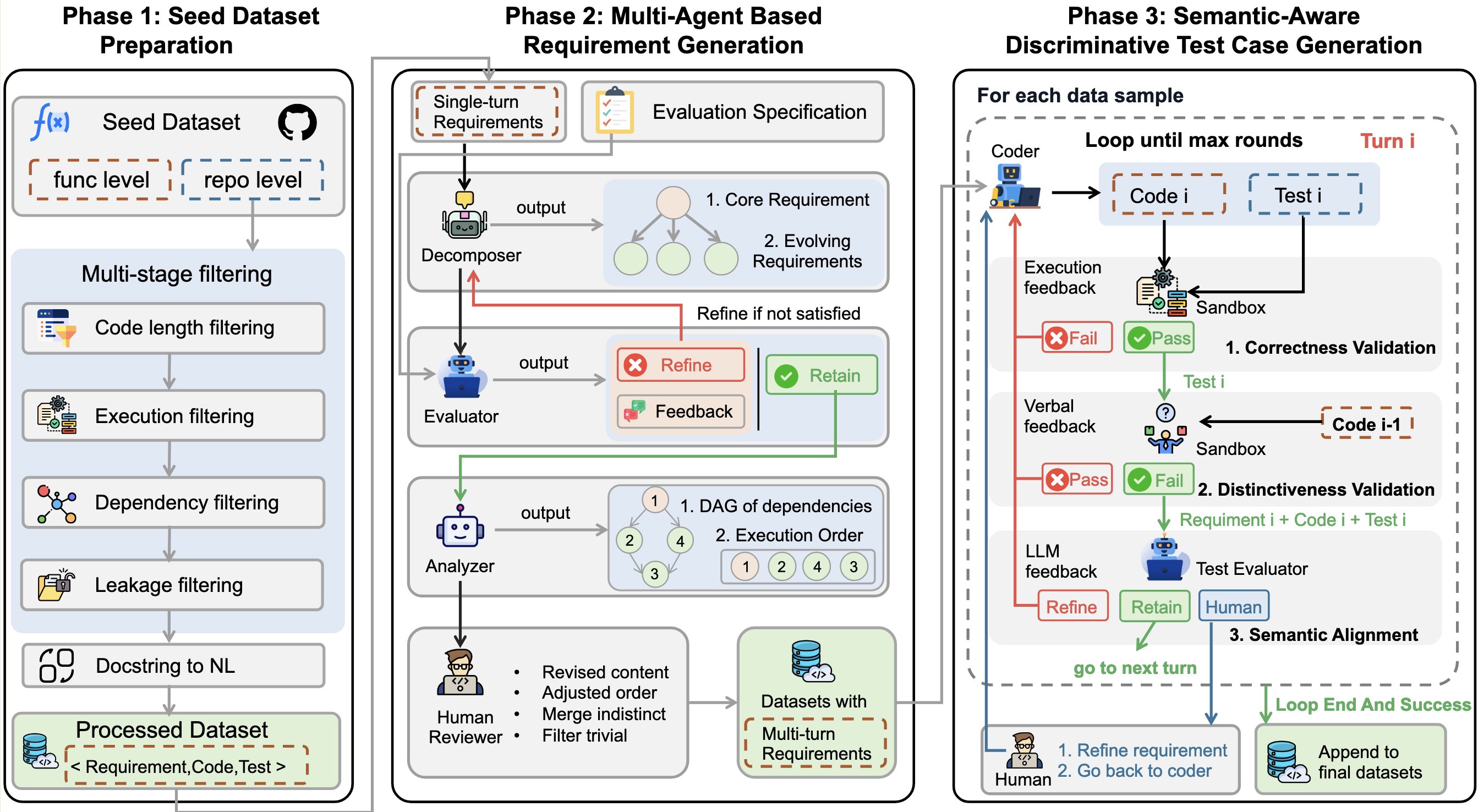
数据
- 种子数据准备:基于单论数据,拓展延伸出多轮数据。
- 数据收集:对于func级别,从 BigCodeBenchHard 收集了148个Python任务,从 AutoCodeBench 收集了188个Java任务。对于repo级别,从 DevEval 收集了1,825个Python样本,从 MRGBench 收集了106个Java样本。
- 数据处理:留下适用于多轮对话的数据,删除过短的,跨文件的,避免搜索功能带来干扰。
多智能体
- 分解器:负责将复杂需求拆解为一个核心功能与多个补充需求,不预设固定执行顺序。总共2到5轮。
- 评估器:负责评估分解后需求的质量,并在必要时提供可操作的改进建议。
- 分析器:负责分析分解后的需求,构建有向无环图以呈现依赖关系,并确定最终执行顺序。
评测
Testability / Completeness / Distinctiveness / Scenario Authenticity
流程:$Generate \to Correctness\ validation \to Distinctiveness\ validation \to Semantic\ Alignment$
先验证正确性,再验证测试是否全面,是否为旧功能就可以完成的测试,确保模型不作弊。
最后语义对齐的时候,会有三种输出:
- RETAIN (保留): 评审通过,测试完美符合需求语义。
- REFINE_TEST (优化测试): 代码没问题,但测试用例的写法、命名或断言信息与需求描述有出入。生成反馈要求 Coder 修改测试。
- REFINE_REQUIREMENT (优化需求): 评估者发现需求本身模棱两可或有逻辑漏洞,导致无法编写准确的测试。此时触发人工介入 (
human_interrupt) 来修正源头需求。
实验设计
- RQ1:LLM在迭代式代码生成中的表现.
- RQ2:不同提示策略如何影响LLM在迭代代码生成任务中的性能?
- RQ3:本研究提出的测试用例生成策略在提升测试用例质量与判别能力方面的效果如何?
实验变量
prompt设定
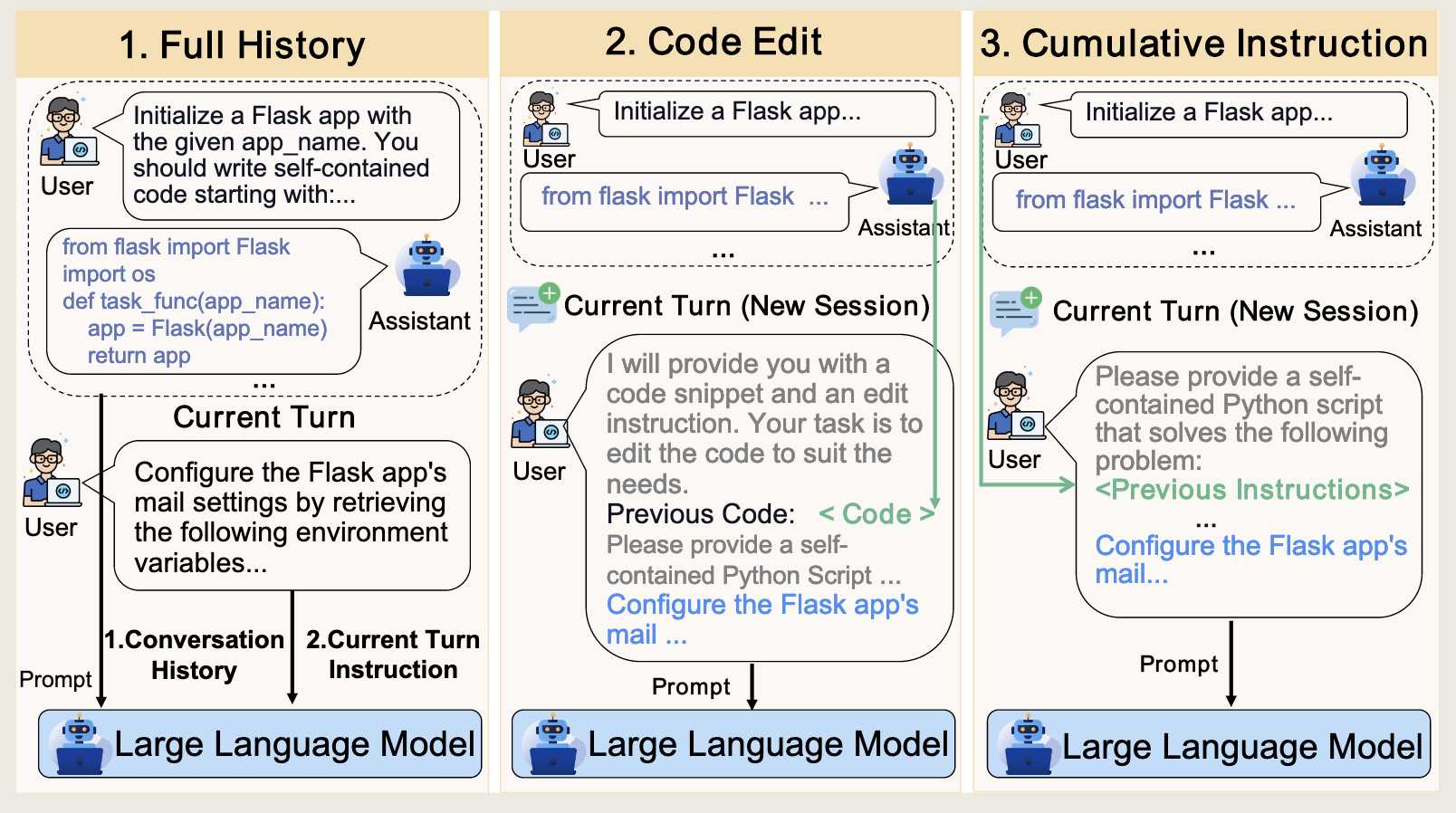
- Full History (FH):把之前所有轮的用户指令 + 模型代码回复全部塞进 prompt
- Code Edit (CE): 每轮开一个新对话,只提供 上一轮的代码 和 当前轮的新指令(要你基于该代码修改)
- Cumulative Instruction (CI):一次性提供所有历史指令,模型从零开始写作
上下文设定:
- Basic Setting(BS):历史代码都是真实地用“模型上一轮的输出”
- Golden Setting(GS):历史代码统一替换成“参考实现(正确答案)”,模拟有人类/工具帮你把前几轮代码修到完美后,再进入下一轮
实验结果
RQ1
在 BS 下,完整完成率20%不到。GS 下,完整完成率25%左右,Java提升明显。
Qwen3-235B vs Qwen3-30B,不论函数级还是仓库级,大模型准确率和完成率都挺高的(235B的比30B的高10%左右)。
DeepSeek-V3.1-Think 在函数级 Python 上反而弱于普通 DeepSeek-V3.1(46.7% vs 50.6%),Java 上也是类似。
结论:表现普遍不佳,即使是最先进的模型(存疑,其只用到GPT-5-mini-medium thinking),表现也有限。Thinking不一定有用,模型大小不一定有用。
RQ2
综合来看,CE 的成功率是最高的。token较FH少30%左右,完成率稍高。 CI不怎么经济,但是有时候会拿到最高分数。FH没啥优势,又贵效果又不好,但是最接近与ChatGPT对话的方式。
RQ3
用“模型在数据集上的准确率”反过来衡量测试的“刁钻程度”:测试越刁钻,模型越难过关 → 准确率越低。
他们构造了三种版本的数据集(函数级):
- Ours:完整策略(区分度验证 + 语义对齐 Evaluator 都开启)
- w/o Evaluator:只去掉语义对齐,保留区分度验证
- w/o Distinctiveness & Evaluator:两个模块都关掉,只做最基础的正确性检查
用 4 个代表性模型,在这三种数据上重新评测。
删掉模块后,相比Ours成功率都显著提升,证明模型是有在“作弊”。也说明Ours是严格的。
贡献
首个系统关注多轮迭代的工作。
多 agent 需求生成,语义感知判别。
发现 thinking 模型可能想多了然后做错。
上下文裁切是有必要的。