China3DV 听会笔记
整理 China3DV 期间关于 3D/4D 重建、生成、世界模型与具身智能的听会笔记。
本文档整理了 China3DV 前两天的笔记。
4.17 上午
NeoVerse



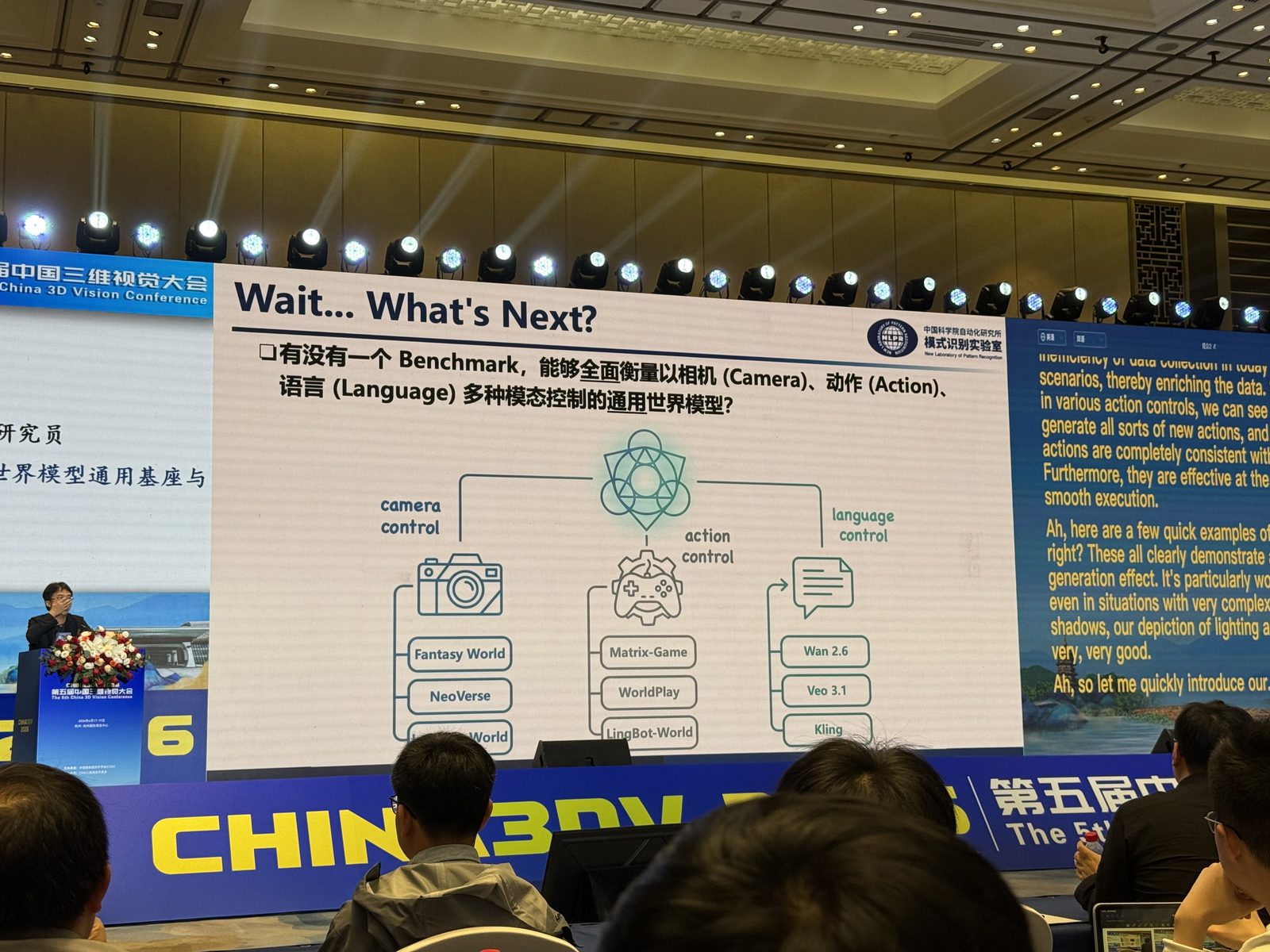

4DGS,张兆翔 可视、可控、可推演的通用 4D 世界模型。从 JEPA 到 Genie3 到 Marble 到其追求的「重建+生成+规模化」的技术路径。要把 single-view 的互联网视频,变成能支撑 multi-view / 4D 建模的训练资源。
从输入视频出发,先做前馈重建,得到动态 4D Gaussians 表达,再通过 novel view rendering 产生多种退化后的渲染信号,比如 depth、mask、RGB、Plücker 等,再把这些信号接回视频生成模块,形成一个更紧的“重建 + 生成”闭环。slides 里强调了几个关键词:4D 显式表征、可推演、可扩展、秒级重建、通用框架、面向通用场景、高速生成。
同时处理 camera control、action control、language control,也就是不只是“看见世界”,还要“控制世界、描述世界、推演世界”。
4D空间视频生成/编辑



周晓巍 先用 InfiniteStudio 做了一个 Live Demo,展示“沉浸式 4D 空间视频 / volumetric capture for film making”的效果;
然后从 多相机阵列环绕拍摄 讲到更 practical 的方向,也就是 从 monocular video 做 reconstruction。中间强调了两件事:一是 real-time,二是表示方式要更紧凑、更一致,减少时空冗余。接着进入 4DGS scene editing / 4D segmentation,核心想法就是把多视角 2D segmentation 和 3D tracking 结合起来,得到更稳定的 4D segmentation,再往下游走到 4D relighting / editing。最后一页把结论拔高到 from 4D reconstruction to 4D generation:相比 2D video generation,4D generation 的优势在于 consistency、controllability、real-time interactivity,并且更容易和 physics / graphics / robotics 结合。
工作介绍:
- InfiniteStudio: 4D Volumetric Capture for Film Making and Beyond:面向 film making 的 4D volumetric capture / 空间视频系统,强调高质量拍摄、沉浸式展示和后期可编辑。
- Relightable and Animatable Neural Avatar from Sparse-View Video:从 sparse-view video 重建可动画、可 relight 的 neural avatar,同时建模几何、材质与光照。
- Split4D: Decomposed 4D Scene Reconstruction Without Video Segmentation:不依赖 video segmentation,做 decomposed 4D scene reconstruction / 4D segmentation,时空一致性更好。
- 4DGT: Learning a 4D Gaussian Transformer Using Real-World Monocular Videos:从 real-world monocular videos 学习 feed-forward 的 4D Gaussian Transformer,用于 dynamic scene reconstruction,强调 monocular、效率和一致性。
Modeling the World from Reconstruction, Simulation and Action





Modeling the World from Reconstruction, Simulation and Action
Computer vision as we know it is about to go away. 更准确地说:CV 没有消失,而是在被 absorbed into World Modeling。
World Model = perceive structure + simulate dynamics + drive action
Talk Roadmap: Perception (“Eyes”) -> LingBot-Map Simulation (“Brain”) -> LingBot-World Action (“Hands & Feet”) -> LingBot-VA
Map
Geometric Context Transformer for Streaming 3D Reconstruction
LingBot-Map -> streaming 3D reconstruction / real-time scene understanding
RNN -> Memory; KV Cache -> Memory;
Insight from SLAM 对应关系:
- Reference Frame -> Anchor Context
- Global Map -> Trajectory Memory
- Local BA -> Local pose-reference window
Bitter Lesson;
效果:最长测到 200km 左右可以重建得好
补充一点:LingBot-Map 在结构上并不 SLAM,而是一种 NSA,将长上下文拆成local + compressed/global + selected 之类的分支,用层次化稀疏模式兼顾全局感知和局部精度。LingBot-Map 用结构化稀疏上下文替代全量 attention,思路和 NSA 很像。
World
Advancing Open-source World Models
LingBot-World -> world simulator / simulation
理解: World 这一部分更像把 reconstruction 往 dynamics / simulation 推进,不只是看见 3D 结构,而是让模型持续生成、保持一致、可交互。
VA
Causal World Modeling for Robot Control
LingBot-VA -> action / robot control
理解: 预测下一个 frame,同时预测中间动作,再给机器人执行。 不是纯 reactive policy,而是 world modeling + action 一起做。
Simulate Dynamic 3D World





吴尚哲 视觉的核心目标可以概括为 what is where:语义识别回答“这是什么”,几何推理回答“在哪里、结构如何”。但报告强调,视觉不应停留在静态识别与几何恢复上,而要进一步走向 from pixel to motion。这里的 motion 也 not limited to multi-view geometry from ego-motion:不只是从相机运动里恢复 3D shape / pose,而是要从 motion of the entire world 里抽取 dynamics / kinematics / physics,理解物体如何运动、受什么约束。走向 3D 的意义在于同时支撑 controllable visual generation、robotics & engineering 和 science,最终建立对真实物理世界更准确、更一致、且可验证的表示与模拟方式。
- Particulate: Feed-Forward 3D Object Articulation:给定一个 single static 3D mesh,直接用前馈方式预测这个物体的 3D parts、kinematic structure 和 motion constraints。它的重点不只是“把物体分成几块”,而是进一步恢复这些部分之间怎么连接、能绕什么轴转、能如何运动,因此更接近 articulation / kinematics,而不是普通几何分割。相比逐物体优化的方法,它是一次前向推理完成,速度更快,也能处理 AI 生成的 3D asset。
- NeuROK: Generative 4D Neural Object Kinematics:这条工作更偏向 generative 4D object kinematics。如果说 Particulate 更像是从静态 mesh 中恢复“这个物体的关节和可动结构”,那 NeuROK 更进一步,关注如何用生成式方式表示和建模物体的 4D motion / kinematic behavior,把“物体会怎么动”本身变成可学习、可生成的对象。公开作者主页能确认这篇 work 已列出,但这次没有检到公开 arXiv 链接。
- Choreographing a World of Dynamic Objects:这篇工作的重点已经不只是单个物体的 articulation,而是进一步走向 dynamic 4D scenes。它提出的 CHORD 管线,试图从 2D video generative models 中提取隐藏的 Lagrangian motion information,从而让一组原本静态的 3D objects 生成多物体、可交互的动态场景。可以理解为从“一个物体怎么动”推进到“多个动态物体构成的世界如何一起演化”。
生成理解3R



陈安沛 陈安沛这场主要在讲,world model 更接近“对现实的预测”,而不只是对视频像素序列做统计拟合。报告把 simulate reality 的技术路线大致分成三类:一类是 video generation,直接预测 raw pixels,优点是视觉保真度高、动态变化自然;一类是 spatial intelligence / 3D,显式构建 3D geometry,因此更容易保证结构一致性和显式控制;还有一类是 latent representation,更接近 LeCun 那条在抽象 latent state 中预测未来的思路,重点是节省计算并聚焦高层因果关系。真正的问题不是在这三条路里选一个,而是怎样把它们统一到动态世界建模里。结合 FSD、LLM、VLM 这些例子,他想强调的是:今天真正成功的大模型几乎都建立在人类知识或人类先验之上,因此 dynamic world model 也不能脱离先验,而一个自然的建模方式就是 object-centric——把世界看成由对象实例组成,认为时空变化主要由 instance-level motion 驱动,再借助 Objaverse 这类大规模 3D object 数据提供 foundational human priors。这样 world model 才不只是“预测下一帧长什么样”,而是能同时建模 3D 结构、对象、运动和未来变化。
Motion 3-to-4: 3D Motion Reconstruction for 4D Synthesis:这项工作对应速记里的 “Motion 324 -> 3D 合成”。它把 4D synthesis 拆成两个更稳定的部分:先有 static 3D shape,再做 motion reconstruction。具体做法是从单目视频、外加一个可选的 3D reference mesh 出发,围绕 canonical mesh 学一个紧凑的 motion latent,再预测每一帧的 vertex trajectories,最终恢复出时序一致的 4D dynamic object。相比直接从零生成 4D 世界,这种方式先抓住稳定的 3D 几何骨架,再从视频里恢复运动,geometry 和 motion 的分工更清楚。
汤思宇 4D Perception as a Foundation for Surgical

GGPT: Geometry-Grounded Point Transformer:这是一个把 feed-forward 3D reconstruction 和 sparse multi-view geometric guidance 结合起来的方法。它的核心思路不是只靠网络直接“猜”出稠密几何,而是再引入可靠的稀疏几何约束来纠正结构误差,所以相比纯前馈方法,几何一致性更好、细节更准、跨域更稳;论文里还特别提到它在 medical / surgical scenes 这类 out-of-domain 场景里更有优势。
2D 观测实现完整 3D 建模


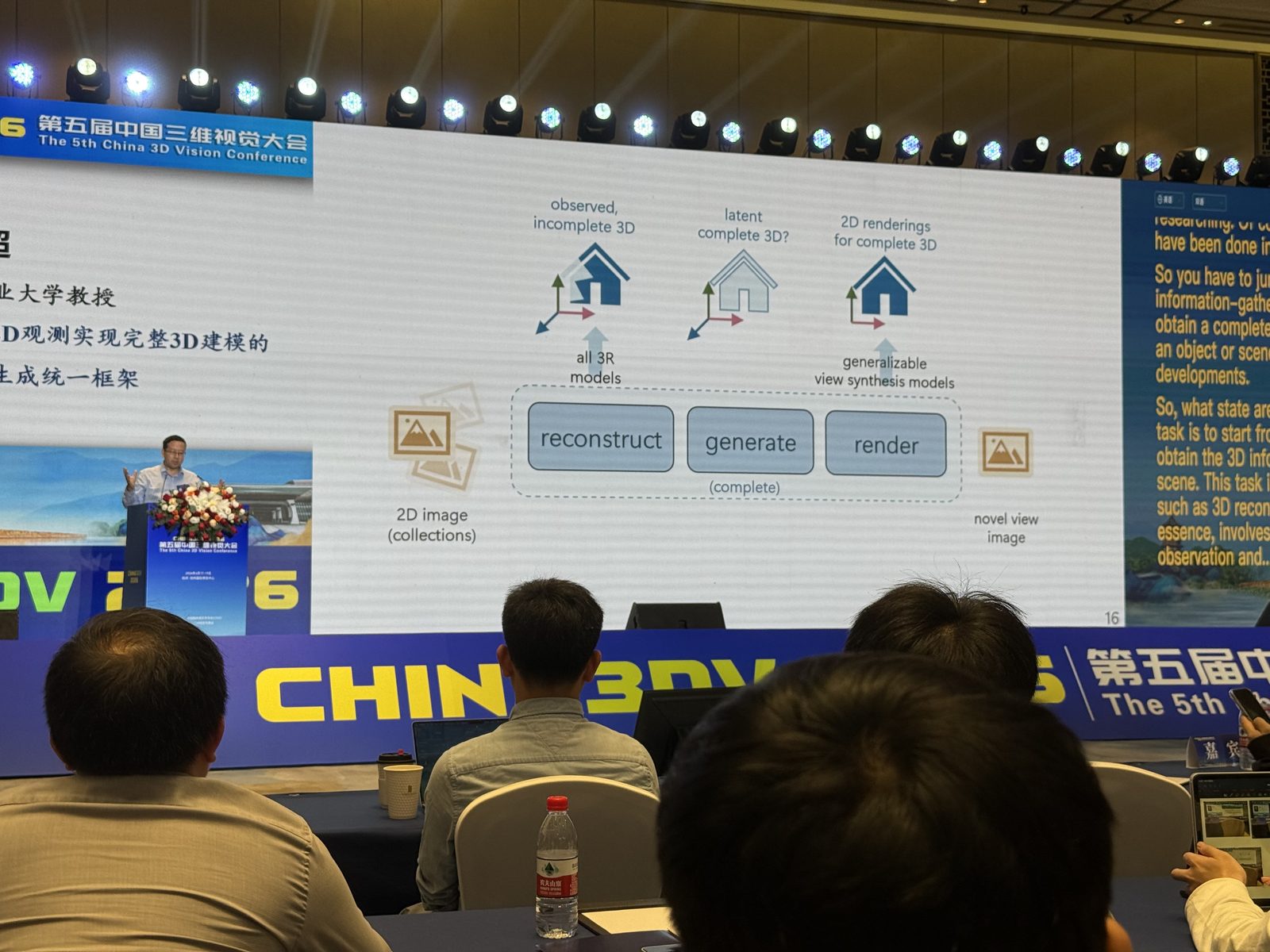



戴玉超 从 partial 2D observations 出发,完整 3D 建模不该只做“看见什么就重建什么”,而应该把 reconstruct / generate / render 放进同一个统一框架。传统 feed-forward 3D reconstruction,哪怕像 VGGT 这样很强的几何基础模型,也更擅长恢复已观测区域的相机、深度、点图和几何结构;但对于未观测部分,通常还是缺乏显式建模。报告想推进的是:真实输入天然不完整,目标就不该只是从 2D 到 incomplete 3D,而应进一步估计 latent complete 3D,再从这个完整表示里做 novel-view rendering。这个角度下,重建负责 fidelity from reality,生成负责 completion from partiality,rendering 则把统一的 3D 表示重新投影成可见图像。
VGGT: Visual Geometry Grounded Transformer:这是报告里很重要的前置背景。VGGT 的强项是从 one / few / many views 的 unposed 图像中,直接前馈预测相机参数、point maps、depth maps 和 3D tracks,说明 feed-forward 3D reconstruction 已经可以把“从图像恢复几何”做得很强、很快。报告里把它当作一个出发点:VGGT 很擅长 reconstruction from observation,但它的表示更偏向已观测区域,因此自然会引出下一个问题——能不能在此基础上继续走向 complete 3D modeling,而不只是 observed geometry。
RnG: A Unified Transformer for Complete 3D Modeling from Partial Observations:这篇就是这场报告的核心工作。它的目标非常直接:给定少量 unposed images,不只恢复 visible geometry,而是直接预测一个隐式的完整 3D 表示,让模型同时具备 reconstruction 和 generation 两种能力。关键设计是 reconstruction-guided causal attention:在 attention 层面区分“重建已观测部分”和“生成未观测部分”,同时把 KV-cache 当成隐式 3D representation。它不是先做一个 3D reconstruction 再额外接 generation 模块,而是在 transformer 内部把两者统一起来,让 From KV cache to generation 成立。这样既能准确重建可见部分,又能补全不可见几何与外观,并保持 multi-view consistency 和实时交互能力。
4.17 下午
Cupid




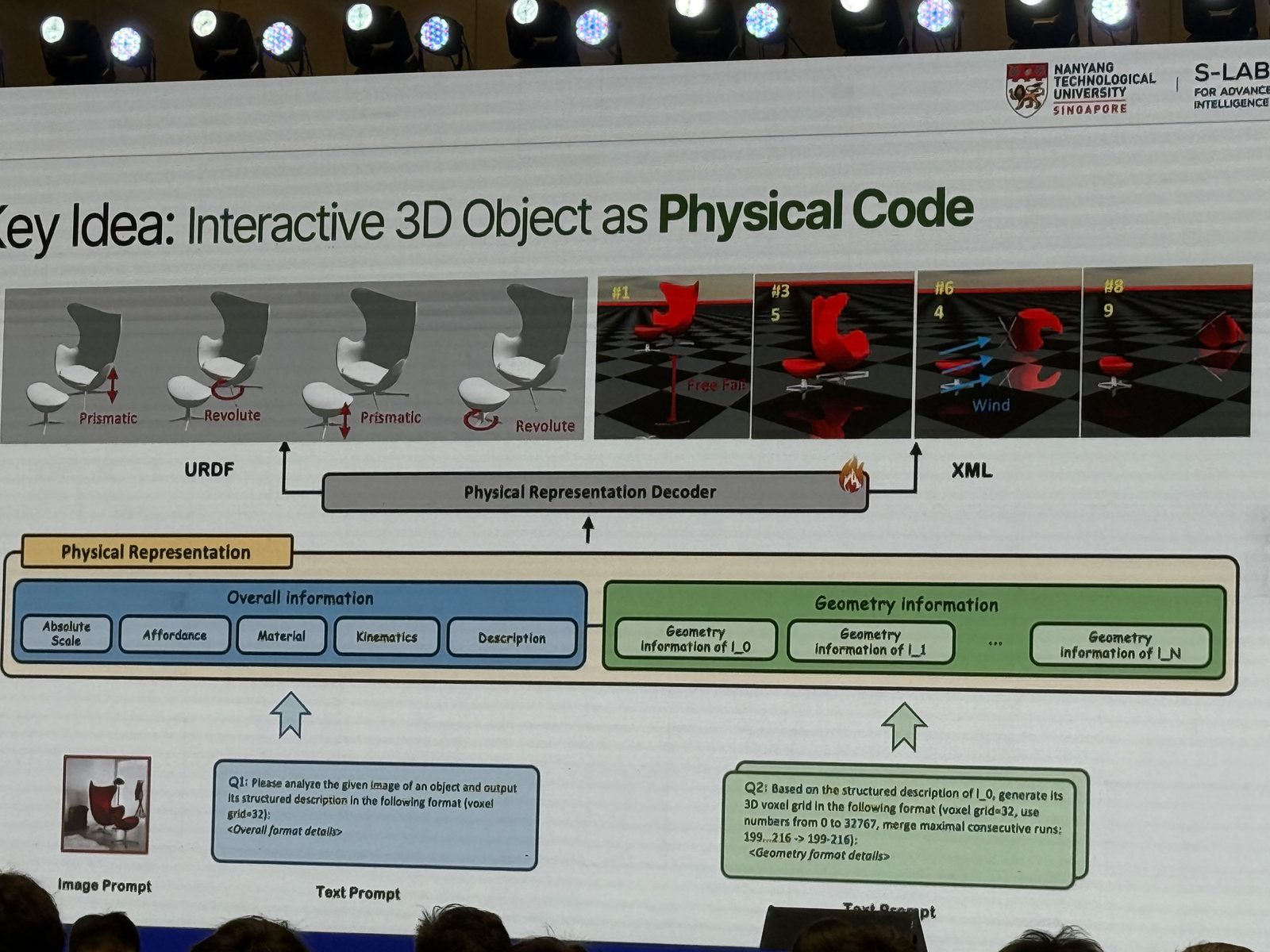
高盛华 这场报告把单张图像 3D 重建重新表述成了一个更“生成式”的问题:不是先默认相机姿态已知、再去恢复物体,而是把物体本身和相机姿态一起建模。这个视角很关键,因为很多 2D 到 3D 的不稳定,本质上都来自 pose 没有被显式表示。报告里反复强调的是“canonical object state / object-centric camera”:如果模型能先把输入映射到典型物体坐标系里,再去补全几何和纹理,那么 reconstruction 得到的不只是 visible surface,generation 也不会完全脱离输入图像约束。对具身来说,这个思路也很自然,因为统一的操控范式往往依赖统一的物体参考系,而不是每次观测到的偶然视角。
方法上,Cupid 采用了一个两阶段流程:先从单视图里联合生成 coarse shape 与 pose,再在 pose-aligned 的条件下生成精细几何和外观。这样做的意义是把“2D 像素信息应该落到 3D 的什么位置”这件事显式化,而不是让它隐含在黑盒 latent 里。报告最后一句话也很有代表性:缺失的 pose,正是连接 3D reconstruction 和 3D generation 的桥梁。重建因为它获得 imagination,生成因为它获得 consistency with input。
Cupid: Generative 3D Reconstruction via Joint Object and Pose Modeling:高盛华这场报告的核心工作。项目页里把思想写得很清楚:单张图像 3D 重建不应只做 geometry fitting,而应显式联合建模 camera pose、shape 和 texture。
From 2D to 3D Generation: Where Should 3D Live in Video Diffusion Models?



廖依伊 这场报告问了一个很好的问题:从 2D video diffusion 走向 3D generation 时,3D 到底应该“活”在哪一层? 仅靠 2D 视频模型去生成,再事后做重建,往往会出现几何漂移、相机轨迹不稳定、multi-view inconsistency 等问题。也就是说,3D 不能只在输出阶段被“读出来”,它必须在生成过程内部占有明确位置,至少要体现在相机控制和几何 latent两个层面上。
这条线索在报告里主要落成两件事。第一是 ReRoPE:不是重新训练整个 video diffusion model,而是把相对相机位姿注入到 RoPE 中原本没有被充分利用的频段里,从而以 plug-and-play 的方式给模型增加 camera control,缓解生成视频重建后的 drifting。第二是 Gen3R:不是把 reconstruction model 解码成图像后再送回 diffusion model,而是直接在 latent space 里对齐 reconstruction 和 generation。速记里记下的 “VGGT -> adaptor -> Wan VAE / KL loss” 对应的正是这个桥接思路:让几何 latent 和外观 latent 在统一空间里相遇,避免 decode-reencode 带来的损失。
ReRoPE: Repurposing RoPE for Relative Camera Control:把 relative camera pose 直接注入 RoPE,用很轻量的方式提升视频生成中的视角控制能力。
Gen3R: 3D Scene Generation Meets Feed-Forward Reconstruction:把 feed-forward reconstruction 的几何先验和 video diffusion 的外观先验在 latent space 里对齐,是这场报告里“bridge generation and reconstruction”的核心代表。
三维生成:我的具身初体验






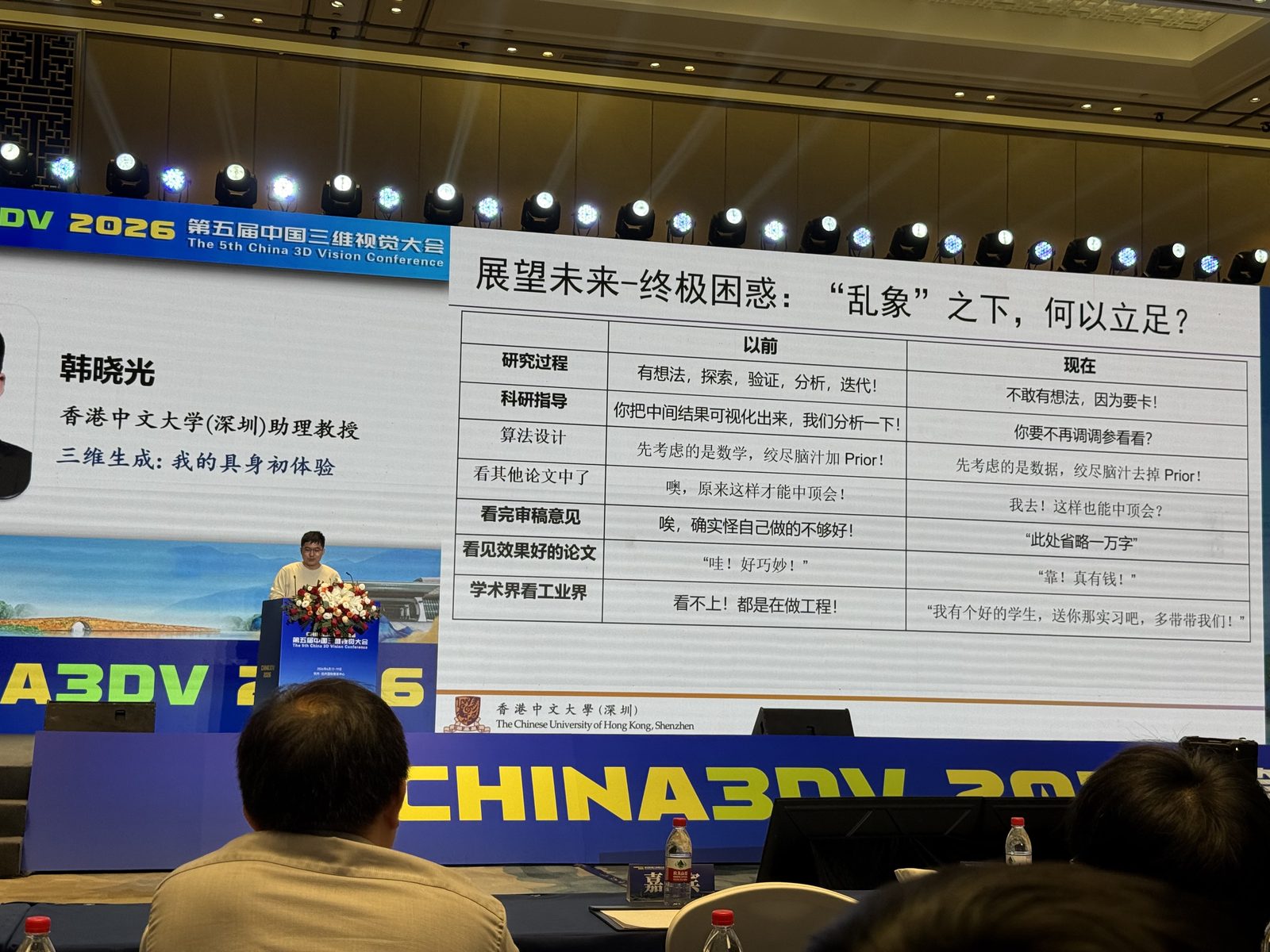


韩晓光 这场更像一份从 3D 生成转向具身智能的研究者自述,而不是单篇论文汇报。比起直接讲一个技术系统,韩晓光更关心的是:为什么很多做 3D generation 的人会转向 embodied intelligence?报告把阻力拆成了选题、工程、评审、学术与工业错位等几个层面,重点不是“某个方法特别新”,而是跨方向时的真实阻力。
但如果把速记和几页技术 slide 合起来看,这场报告想说的主线仍然很清楚:3D 生成如果不能进入 interaction / simulation / control 的闭环,就还离 physical intelligence 很远。 一条线是从人的交互视频中学可操作对象,例如 ForeHOI 试图直接从日常 hand-object interaction 视频中做前馈式 3D 物体重建;另一条线是用更原生的 3D foundation model 去支撑后续任务,例如 Omni123 试图把 text-to-2D 和 text-to-3D 放进同一个 3D-native 自回归框架里;再往下就是更具工程意味的仿真与 benchmark 路线,像 slide 里出现的 RoboTwin,它代表的是“先把可训练、可评测、可泛化的双臂操作数据和环境建起来”。
ForeHOI: Feed-forward 3D Object Reconstruction from Daily Hand-Object Interaction Videos:从严重遮挡的 hand-object interaction 视频里直接恢复物体 3D,是“learn from human interaction”这条线的代表。
Omni123: Exploring 3D Native Foundation Models with Limited 3D Data by Unifying Text to 2D and 3D Generation:把 2D 与 3D 生成统一到共享序列空间里,代表报告里提到的文生 3D base model 路线。
RoboTwin 2.0:如果说前两者是在补 3D prior,这个项目则更像是在补 embodied 所需的仿真、任务与数据基础设施。
三维资产生成模型 TRELLIS 进展汇报








杨蛟龙 这场报告非常适合拿来理解 TRELLIS v1 到 TRELLIS.2 的演进。TRELLIS v1 的优点已经很强了:它能联合建模 appearance 与 shape,也能灵活解码到 Gaussian、mesh、radiance field 等多种输出形式,泛化性能也好。但 slide 里同样非常诚实地列出了它的限制:它的编码仍然依赖 multiview-rendering based encoding,本质上不够 3D-native,信息会丢;对 open surface、non-manifold、interior structure、material 的支持也都不够;latent 也还不够 compact。这些问题并不是“多堆一点算力”就会消失,而是 representation 本身要重做。
所以 TRELLIS.2 的思路不是简单升级 base model,而是重做整套 3D latent 栈。slide 上四个关键词总结得非常清楚:O-Voxel / SC-VAE / SLat GEN / FlexGEMM。其中 O-Voxel 是一种 field-free 的 sparse voxel representation,想解决的是 arbitrary topology 与 rich appearance 的原生表示;SC-VAE 则负责把高分辨率 3D asset 压成更紧凑的 structured latent;随后再用生成模型逐步生成 shape latent 与 texture latent。整个思路就是把 3D asset generation 从“渲染再编码”的间接路线,推进到真正的 native and compact structured latents。
TRELLIS: Structured 3D Latents for Scalable and Versatile 3D Generation:对应 v1 的核心框架,强调统一 structured latent 与多种 3D 解码形式。
TRELLIS.2: Native and Compact Structured Latents for 3D Generation:这场报告真正的重点更新。官方页把 O-Voxel、SC-VAE 和 arbitrary topology / PBR material 支持写得很完整。
3D Representations


张彪 这场报告更像一份3D 表征演化图谱。它讨论的不是某个单点方法,而是一个更根本的问题:在神经网络时代,什么样的 3D representation 才足够支撑 generation、editing、simulation 乃至 world model?传统 mesh、point cloud、implicit field 都各有优势,但真正困难的地方在于三件事很难同时满足:高保真细节、复杂拓扑支持、以及可训练可生成的效率。速记里那句 “not all object watertight?” 抓得很准,因为很多 representation 的问题正是在这里暴露出来。
如果把 slide 和原始笔记对照起来,这场报告大概梳理了三条代表性路线。第一条是 LaGeM / VecSet 一类的 latent representation 路线,关心的是怎样把高分辨率几何压缩成可扩展的多层 latent;第二条是 Geometry Distributions,尝试跳出 iso-surface field 的限制,把几何看成分布,从而更自然地处理 thin structure、non-watertight geometry 和复杂表面;第三条则是最近重新回到mesh-native generation 的方向,像 slide 里提到的 Nexus (Tripo P1.0),目标已经不只是“生成一个看起来像 3D 的东西”,而是尽快生成真正可用、拓扑更干净的 mesh。它提醒了一个很容易被忽略的事实:3D 生成的很多上限,最后都不是被 model size 卡住,而是被 representation 卡住。
LaGeM: A Large Geometry Model for 3D Representation Learning and Diffusion:代表速记里记到的 VecSet 系列思路,即通过分层 latent 压缩来提升 3D 表征的规模与生成能力。
Geometry Distributions:强调几何作为分布而不是单一显式曲面,可更自然地覆盖非封闭、薄结构和复杂拓扑。
Tripo Smart Mesh P1.0:虽然 slide 上写的是 Nexus (Tripo P1.0),但核心信息很明确,就是把 mesh generation 推向更快、更干净、可直接使用的 production asset。
Towards Controllable and Rational 3D Generation via LLMs

刘缘 这场报告想解决的问题可以概括成一句话:现有 3D 生成模型常常“能生成”,但不一定“讲道理”。 单视图 3D 或文生 3D 往往在正面看起来不错,但背面细节、遮挡区域、部件关系和场景布局很容易变成随机 hallucination。于是 LLM / VLM 在这里扮演的角色,不再只是 prompt rewriter,而是一个负责补足常识、分解任务、约束隐藏结构的 reasoning module。换句话说,报告里的 “rational” 不是指生成更漂亮,而是指生成结果在 unseen regions、scene composition 和 part semantics 上更可解释、更可控。
速记里记到的几个关键词基本都围绕这个方向。Know3D 很典型:它把 vision-language model 的知识引入 3D 生成过程,目的就是减少背面与不可见区域的随机性。笔记里还提到一个 layout-agent 思路,本质上也是先让语言模型把场景拆成资产、布局与关系,再调用 3D 生成器逐步落实。另一条线则是 part-level understanding,例如 PartSAM 这种 native 3D part segmentation,会让模型更容易在“椅背、扶手、把手、轮子”这种结构层级上被语言或交互所控制。于是可控 3D generation 的真正含义,不是后处理修修补补,而是让语言模型先告诉系统:该生成什么、为什么这样生成、哪些部分必须满足语义约束。
Know3D: Prompting 3D Generation with Knowledge from Vision-Language Models:把 VLM 知识注入 3D 生成流程,重点就是让 unseen region 的生成不再完全随机。
PartSAM: A Scalable Promptable Part Segmentation Model Trained on Native 3D Data:虽然它更偏 3D understanding,但正好对应笔记里“部件语义 / 分割 / 可控”的那条线。
4.18 上午
Advances in 3D Editing, Consistency, and Control



Daniel Cohen-Or Daniel 这场更像一条从 3D editing / consistency / control 往回追的研究线索。前半段他还是站在 3D 的角度讲问题:矩阵相机 3D、多视图优化过程里同时得到 2D/3D 结果、以及 edit MV view 再回到 3D diffusion 的可能性。这里他反复强调的是,真正有用的编辑框架应该尽量满足几个条件:Native 3D / No masks / Image condition / training-free edit,也就是尽量减少 task-specific 的人工结构,让表示本身承接一致性和控制。
后半段则明显“back to 2D”。他从 conditional diffusion、DDPM、DiT 一路讲到类似 Flux Kontext 这种带强度控制的编辑方式,再把话题收束到 fine-grained control editing:为什么有些 token 不只是 semantic token,而还带有 identity representation?slide 里的 Identity Tuning / Identity Space / Local Attributes Tokens Selection 对应 OmniID / Kontinuous Kontext / SVM / PCA / representation variant direction 这条线。核心直觉是:如果能显式识别“哪些 token 负责什么局部属性”,slider 式连续编辑就不只是经验调参,而是朝着可解释控制前进一步。
Towards Agentic 3D Vision: A Love Story of Academia and Industry

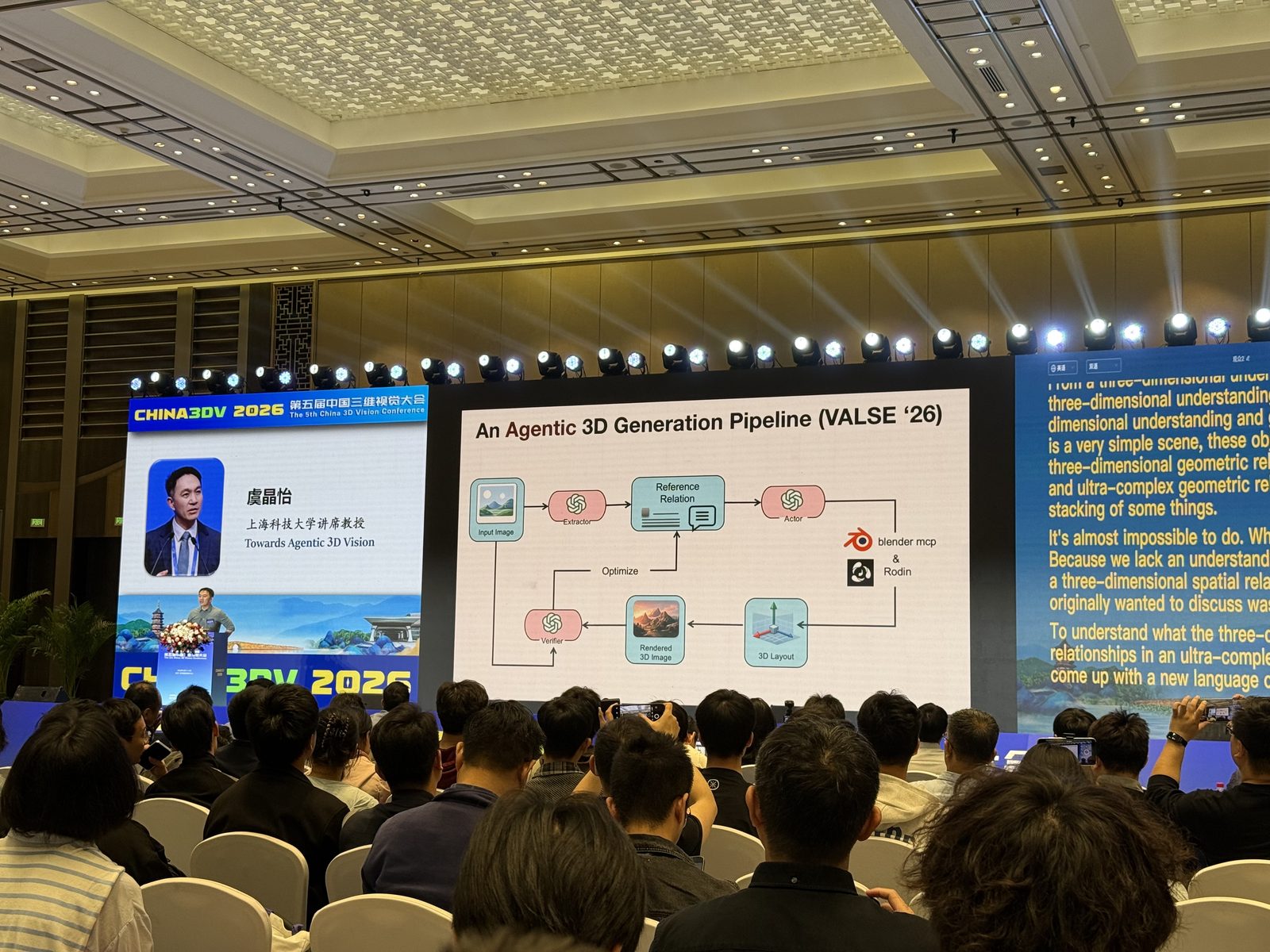



虞晶怡 虞晶怡这场报告的切口很有意思。表面上它在讲 Agentic 3D Vision,但真正的重点其实是“学术界和工业界为什么会一起把 3D Vision 推向 agentic 建模”。一张 slide 上直接写了学生的话:“我听说 3D 视觉已经被做完了,我想去吴老师那里做具身智能,因为他是工业界的。” 这个铺垫很有效,因为它把整场报告从“某个技术点的新工作”变成了“3DV 下一步为什么必须走向 agentic pipeline”的动机说明。
技术上,这场报告给了一个相当具体的 An Agentic 3D Generation Pipeline (VALSE’26):输入图像先经 LLM 抽取 reference relation,再通过 actor 调度 3D layout、Blender MCP、Rodin 等模块,最后回到 rendered 3D image 再做 optimize。它代表的是一种很明确的趋势:3D 生成不再只是单个生成器的能力,而是由 reasoning、relation parsing、3D layout、渲染反馈共同组成的 agentic system。CLAY 和 CAST 分别偏 3D 资产生成与 scene-level 3D generation / reconstruction,刚好把这条路线从 object 到 scene 补齐。
CLAY: A Controllable Large-scale Generative Model for Creating High-quality 3D Assets:更偏 3D 资产生成器,是这场里“工业级 3D generator”那条线的代表。
CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image:从单张 RGB 图像做 component-aligned 的场景级 3D 重建,对应“场景 3D 生成”这条线。
生成式AI赋能世界模型




沈春华 沈春华这场的逻辑很清楚:如果世界模型想往前走,不能只靠更大的 backbone,还得解决高质量 3D/4D 数据从哪里来的问题。slide 里他明确写到一个 observation:foundation models 能从 massive、diverse datasets 里学到 general-purpose representations,而高质量的 3D/4D 数据反而更容易通过 CG rendering / synthetic data 获得。所以他关心的不是单个任务,而是“生成式 AI 怎样反过来成为世界模型的数据与先验来源”。
几组关键词都落在这条主线上:Depth Any Video 是把文生视频、视频先验和 depth estimation 结合起来;Aether / pi^3 / WinT3R / OmniWorld 则覆盖了从 4D reconstruction、generative world model 到多模态 4D 数据集与 benchmark 的不同层面。这场报告不是简单罗列项目,而是在说明:世界模型的发展需要 FM 的 generalization,也需要 CG data 的 controllability 和 quality,二者结合才可能支撑 segmentation、3D generation、3D reconstruction 这些基础视觉任务继续统一。
Depth Any Video:把生成式视频先验用于视频深度估计,是“文生视频到 depth 上面再训练一下”这条线的代表。
OmniWorld: A Multi-Domain and Multi-Modal Dataset for 4D World Modeling:这场报告里关于高质量 4D 数据的重要代表工作。
The Grand Convergence: Unifying 3D Reconstruction and Generation via Diffusion






谭平 谭平这场可以用一句话概括:3D Reconstruction: Constraint-Driven; 3D Generation: Prior-Driven。他把 reconstruction 和 generation 的差别压缩成 Bayes 视角里的 likelihood / prior:reconstruction 更强调观测约束,generation 更强调数据先验。slide 上甚至直接写出 “The Holy Grail: Formulating the Unified Inverse Problem”,把两者统一成 log p(x|y)=log p(y|x)+log p(x) 的问题。这个视角说明两条路线不是冲突的,而是同一个 inverse problem 的两个极端。
后半段围绕 DPS / Route2b / Route3a 展开。DPS 把 diffusion model 用来解 inverse problems in images,本质上是在每个 diffusion step 里显式引入 measurement error 的梯度,而不只是像 SDS 那样把噪声残差当 teacher signal。继续往后,无论是把 DDIM 当可微函数、需要把所有步骤放到 GPU memory,还是把成像算子 A 写成投影矩阵,本质上都是在问:能不能把 diffusion sampling 本身当作更一般的求解器,把 3D reconstruction、3D generation、甚至 3DGC 都放进统一的扩散推断框架里。
Diffusion Posterior Sampling for General Noisy Inverse Problems:这场报告里 DPS 的直接来源,也正是“用 diffusion 解 inverse problem”这条线的经典起点。
From Egocentric Perception to Embodied Intelligence: Building the World in First Person











刘子纬 刘子纬这场的节奏可以概括为:感性 -> 知性 -> 实践。他先从第一人称视角出发,谈 perception 不是终点,而只是 “Perception (ImageNet) -> Geometry -> Action” 里的第一步;再把这个过程提升到一个更大的世界模型愿景里,比如“记录牛顿的所有视频,让世界模型自己发现牛顿定律”。这个说法听起来很理想化,但它的作用是把 egocentric perception 和 embodied intelligence 连到了同一条主线上。
真正的难点还是数据。slide 里写得很直白:物理智能 / 具身智能没有互联网规模的数据,也没有像语言那样便宜、可 scale 的监督。HOMIE - Xperience 不只是一个数据集名字,而是一个试图系统采集第一人称、全景动作、双目场景、in the wild / indoor / outdoor 多模态人类 experience 的方案。报告最后把这个方向落到 Simulation-Ready Modeling 上:好的重建不是看起来像,而是能在仿真器里完成任务。这里他还提到 Phyx-Anything 这类把交互对象进一步走向 physical code / foundation model 的想法,所以 “Simulator as a feedback -> Sim to Real” 在这场里不是口号,而是评判 3D world building 是否真正走向 embodied 的标准。
Interactive Intelligence from Human Xperience:对应 HOMIE,核心是把第一人称 human experience 采集成可训练的结构化数据。
Xperience-10M:更具体的数据落点,覆盖全景、动作、双目场景等多模态记录。
稀疏多视点实时动态三维重建
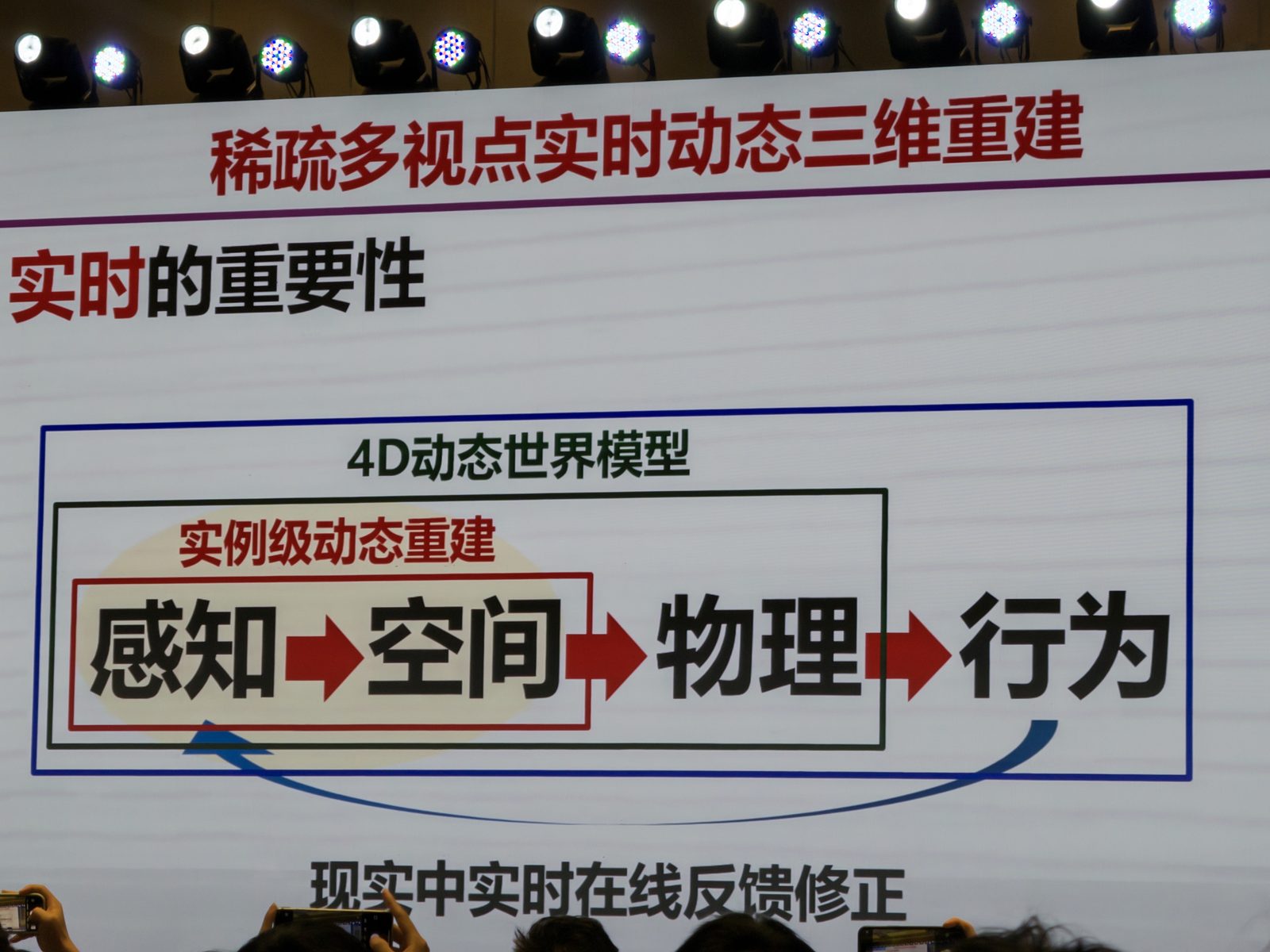









刘烨斌 这场节奏很快,但主线完整。刘烨斌把实例级动态重建放在一个更大的 4D 动态世界模型 路径里来讲:感知 -> 空间 -> 物理 -> 行为,其中实例级动态重建对应的是最靠前、但又极关键的“感知到空间”这一跳。之所以强调实时,是因为现实中的交互和在线反馈修正需要闭环;如果不能闭环,4D 动态世界模型就很难真正走向行为层。
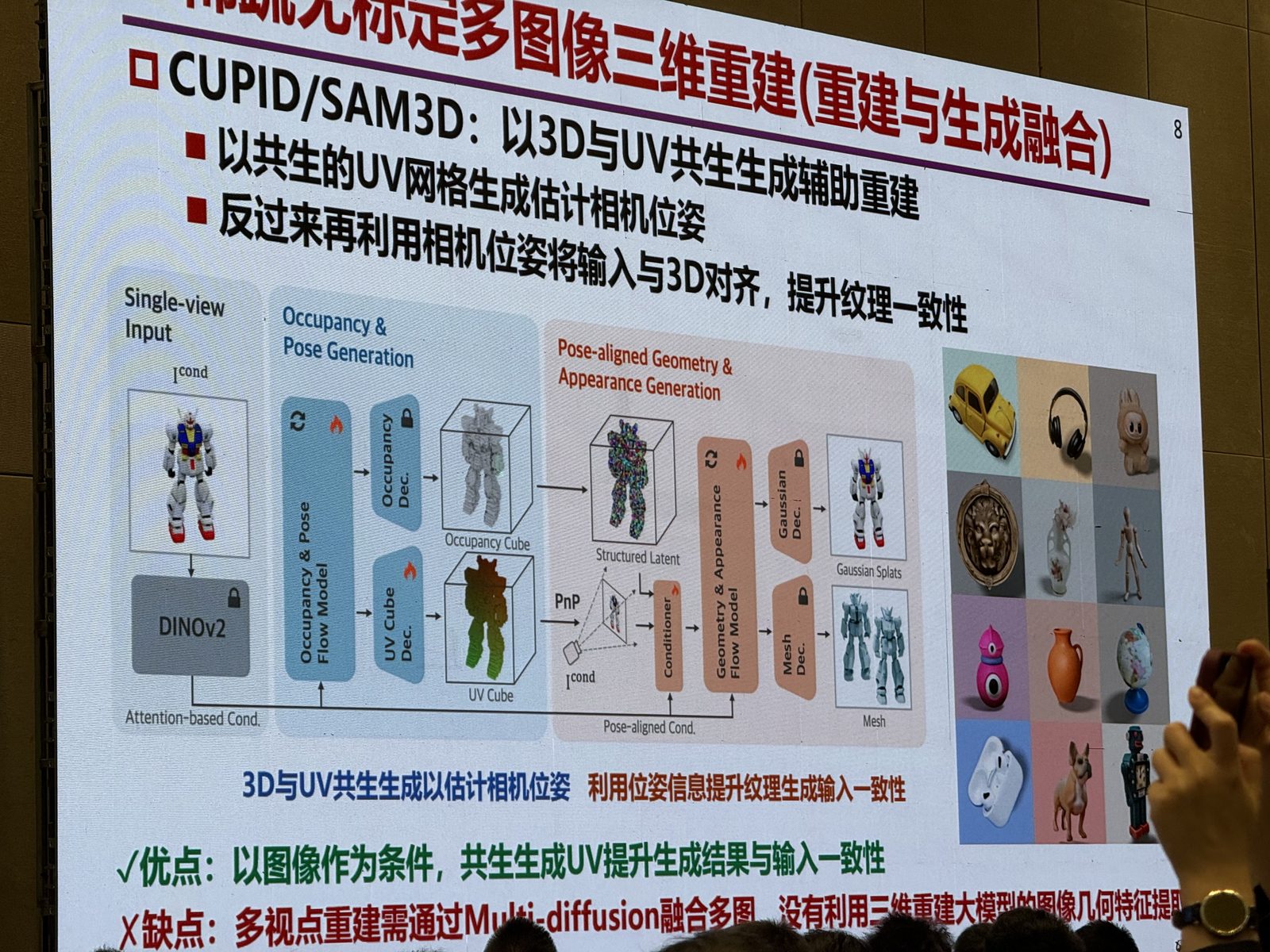
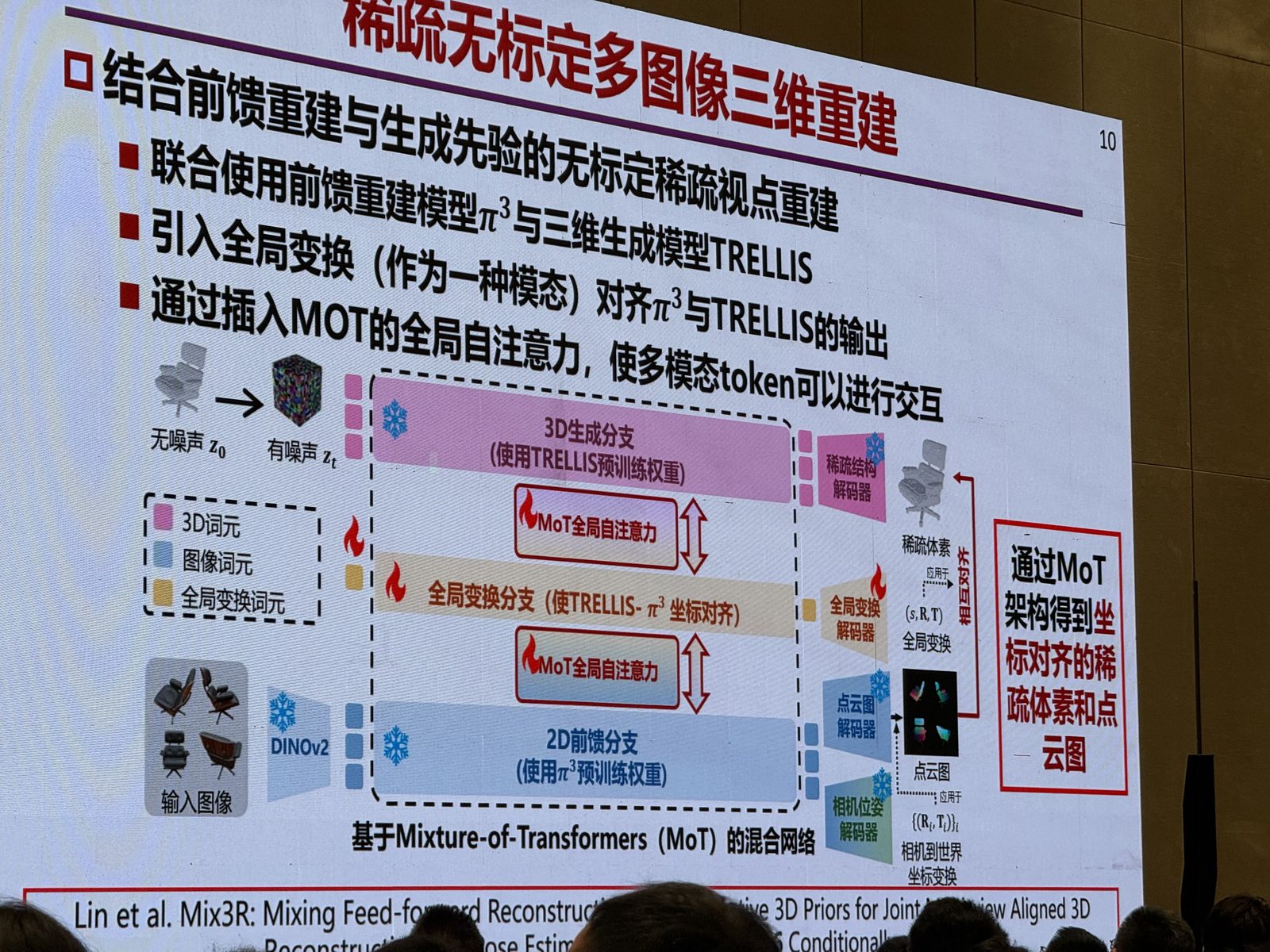
后半段展开“重建与生成融合”。slide 把前馈式多图像三维重建和生成式图像控制重建并排比较:前者像 VGGT,点云与图像像素对齐、一致性高,但无法想象不可见部分;后者像 CLAY / TRELLIS 2 / CUPID / SAM3D,单图也能生成完整模型,但容易在尺度、结构、外观上偏离输入。报告给出的答案是继续把 reconstruction prior 和 generative prior 混起来,例如 ReconViaGen 用 VGGT 特征去条件化 TRELLIS,后面 summary 又进一步提到 Mix3R / Mixture-of-Transformers (MoT):在稀疏、无标定、多视点、动态场景下,把前馈重建和 3D 生成放进统一框架里。
VGGT: Visual Geometry Grounded Transformer:这场里前馈重建那条线的代表。
Cupid: Generative 3D Reconstruction via Joint Object and Pose Modeling:对应 slide 里 CUPID / SAM3D 那部分,用 3D 与 UV 共生生成辅助重建。
TRELLIS.2: Native and Compact Structured Latents for 3D Generation:对应 slide 里 TRELLIS 2,代表生成式 3D prior 的另一端。
4.18 下午
基于重建与生成结合的实时3D世界模型



章国锋 章国锋这场几乎是在给“为什么世界模型最终要走向 3D”做定义。视频生成当然也能预测未来,所以它可以被看成世界模拟器的一种雏形;但单纯的视频 world model 仍然有明显局限:可交互性弱、难以直接影响真实环境、长程一致性和空间持久性不足。因此报告把问题重新表述成“二维到三维升维”的问题:如果模型真的要理解、推演和交互物理世界,它至少要具备 3D 空间中的感知、生成、理解、推演和交互能力。
这也是为什么他把 InSpatio-World 拿出来当代表。slide 上明确写了目标:由单目视频驱动,构建高保真、几何一致、且能实时交互的 4D 动态空间;同时又指出当前方法普遍没有好的记忆机制,长序列漫游容易发生几何突变,交互式漫游任务的数据与训练难度也高。三维空间意味着物体持久、物理规律和一致性空间,真正难的是怎样在这个空间里让“生成 + 重建 + 交互”同时成立。
InSpatio-World:这场里最核心的例子,代表实时交互 4D 动态空间这条路线。
Multimodal Foundation Models with Physical Intelligence


赵恒爽 赵恒爽这场把问题放在 Physical Intelligence 上看:多模态 foundation models 如果想进入物理世界,不能只在 2D 图像和语言之间做对齐,还要把空间表征真正纳入主干。slide 上他先回顾了 Point Transformer V1/V2/V3 的演化,接着把话题推进到 “Spatial Intelligence”:不只做 point cloud perception,而是让点云、图像、视频、地图交互、自动驾驶等任务共享一个可扩展的空间表征底座。
几组关键词可以串成一条清楚的线:PTv3 和 DINOv2 提取空间表征,SONATA 负责让 point representation 更可靠地自监督预训练,Utonia / OneEncoder 则在更高层上追求“更统一的表征”,希望宏观与微观、2D 与 3D、静态与视频都能在同一编码体系里被处理。这场报告真正强调的不是某个单模型,而是:物理智能需要一个既能对齐多模态、又不丢空间结构的 foundation representation。
Point Transformer V3:对应 PTv3,也是这场“空间表征底座”最直接的代表。
Sonata: Self-Supervised Learning of Reliable Point Representations:对应 SONATA,强调 reliable point representation 的自监督预训练。
From Seeing to Understanding: Depth Anything 3 and Beyond




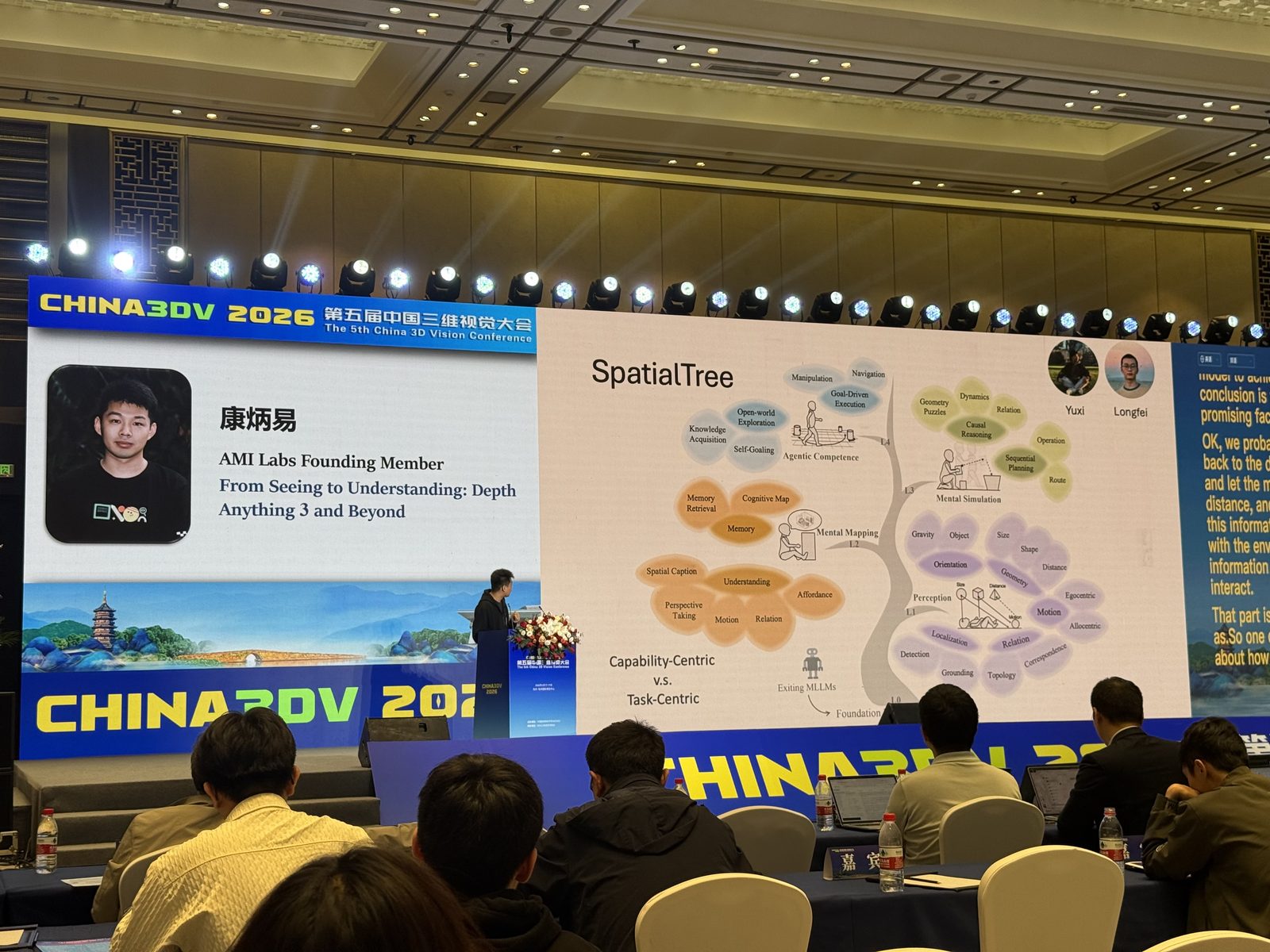



康炳易 康炳易这场的标题就已经说明方向了:From Seeing to Understanding。他不是只想把深度估计做得更准,而是想把 depth 当成通向世界理解的入口。开场问题是“人脑双流机制,语义和空间同样重要”:如果模型只能看懂语义,却没有稳定的空间结构,就很难真正“记录物理世界”。所以从 DA1 到 DA2,再到 Prompt DA / Video DA / DA3,他其实是在问一个更本质的问题:真正的 perception 到底是什么?
这场给出的答案很鲜明:真正的 perception 应该是 multiview 的,而最小空间组成部分是 depth + pose。 slide 里甚至直接写了 “Architecture is just the same as others (wm, llm, etc)” 和 “Pose + Depth is enough for perception”,也就是说他倾向于把 depth model 与 world model / language model 放进同一种 transformer 范式里,只是在输入输出和先验上不同。SpatialTree、low-level 能力正交、高层能力常常绑在一起,也符合这场的逻辑:如果 level1 的空间能力变强,level2、level3 的复杂任务也会跟着提升;但要真正做到这一点,模型还需要合适的 3D prior。
Depth Any Video:是这场里从视频生成先验走向视频深度与空间理解的直接代表。
SpatialTree:把空间能力按层级组织起来,也很贴合这场“从 seeing 到 understanding”的叙述。
面向世界建模和生成的三维、四维表示


齐晓娟 齐晓娟这场更像是从 evaluation 和 representation 两端同时给 world generation 提要求。她先给出一个非常实在的 checklist:理想的 world generation 至少要满足 high-quality visual appearances、temporally and 3D consistent、physically correct、interactive / controllable / editable、long-horizon coherent。换句话说,视频模型现在看起来已经很强,但离真正 simulating the 3D visual world 还有明显距离。
从这个角度看,How Far are AI-generated Videos from Simulating the 3D Visual World 不是一篇普通 benchmark paper,而是在追问:生成视频和真实 3D 世界之间到底还隔着什么。报告里提到用 learned diagnosis 分析 inconsistency,再用 reconstruction-based validation 验证评测结果,本质上是在补“客观 3D 评价”这块短板;3D Spatial Control benchmark 则尝试量化 world model 的空间尺度、控制尺度和真实尺度之间的偏差。最后她又把话题推到 Stereo World Model,强调双目视频比单目更原生、更接近 human perception。这场报告真正提醒的是:如果 evaluation 还停留在 2D 视觉质量,world model 就很容易被错误目标带偏。
How Far are AI-generated Videos from Simulating the 3D Visual World: A Learned 3D Evaluation Approach:对应 slide 上 benchmark results 的主线。
探索视觉Tokenizer预训练扩展定律与新型大模型架构


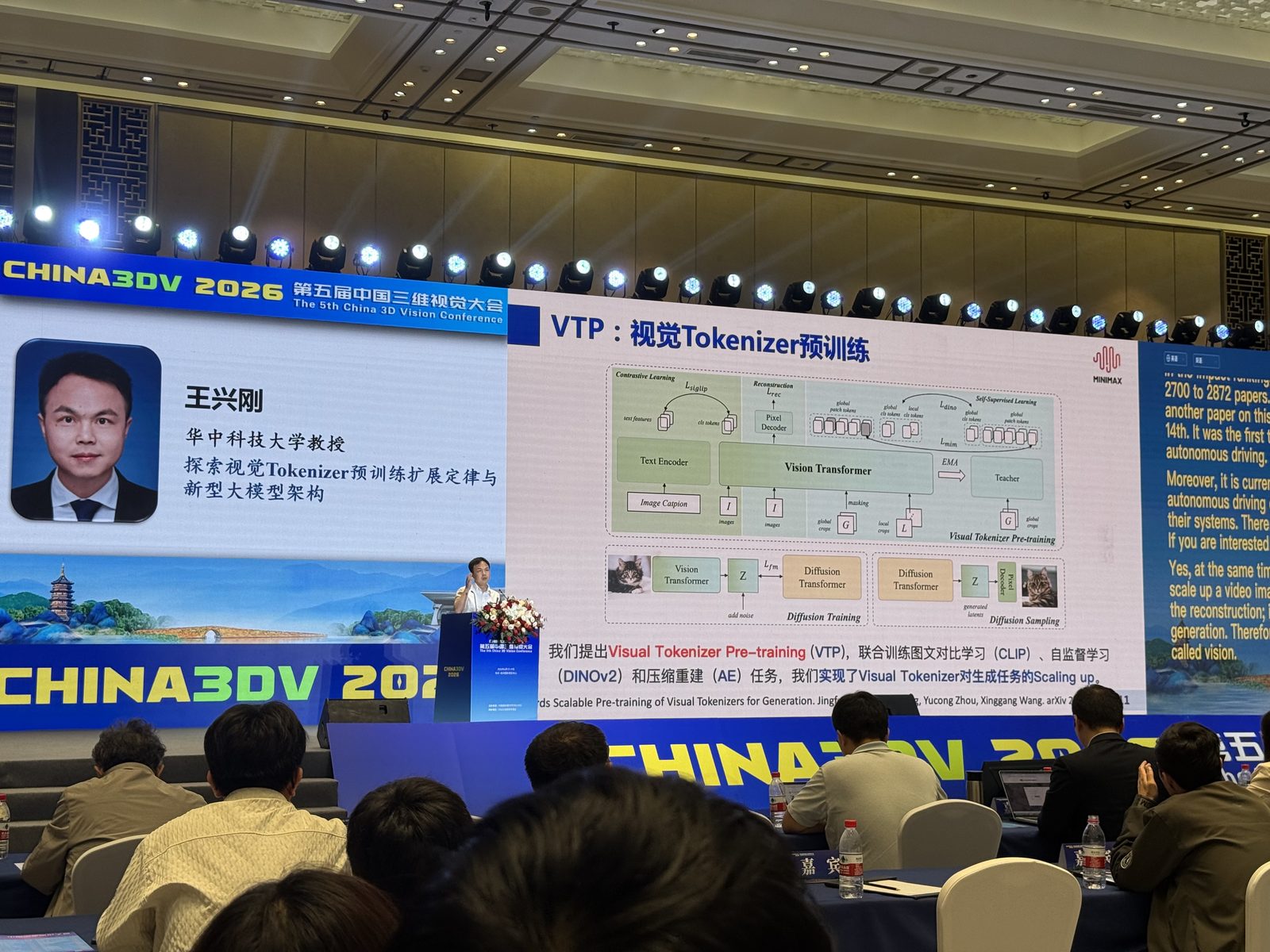



王兴刚 王兴刚这场切得很“底层”。他先从最熟悉的 LDM 框架讲起:先用 VAE 编码,再做 latent diffusion;然后直接抛出问题,“八倍下采样,为什么没人动这个架构?” 这指向一个容易被忽视的前提:当前生成模型已经大规模依赖 visual tokenizer,但 tokenizer 的预训练、scale law 和架构假设,反而长期被当成理所当然。于是 VA-VAE、LightningDiT、VTP、DiffusionDrive 这些词在这场里并不是孤立项目,而是沿着“更好表征 -> 更好生成与理解 -> 更强 scaling”排开的。
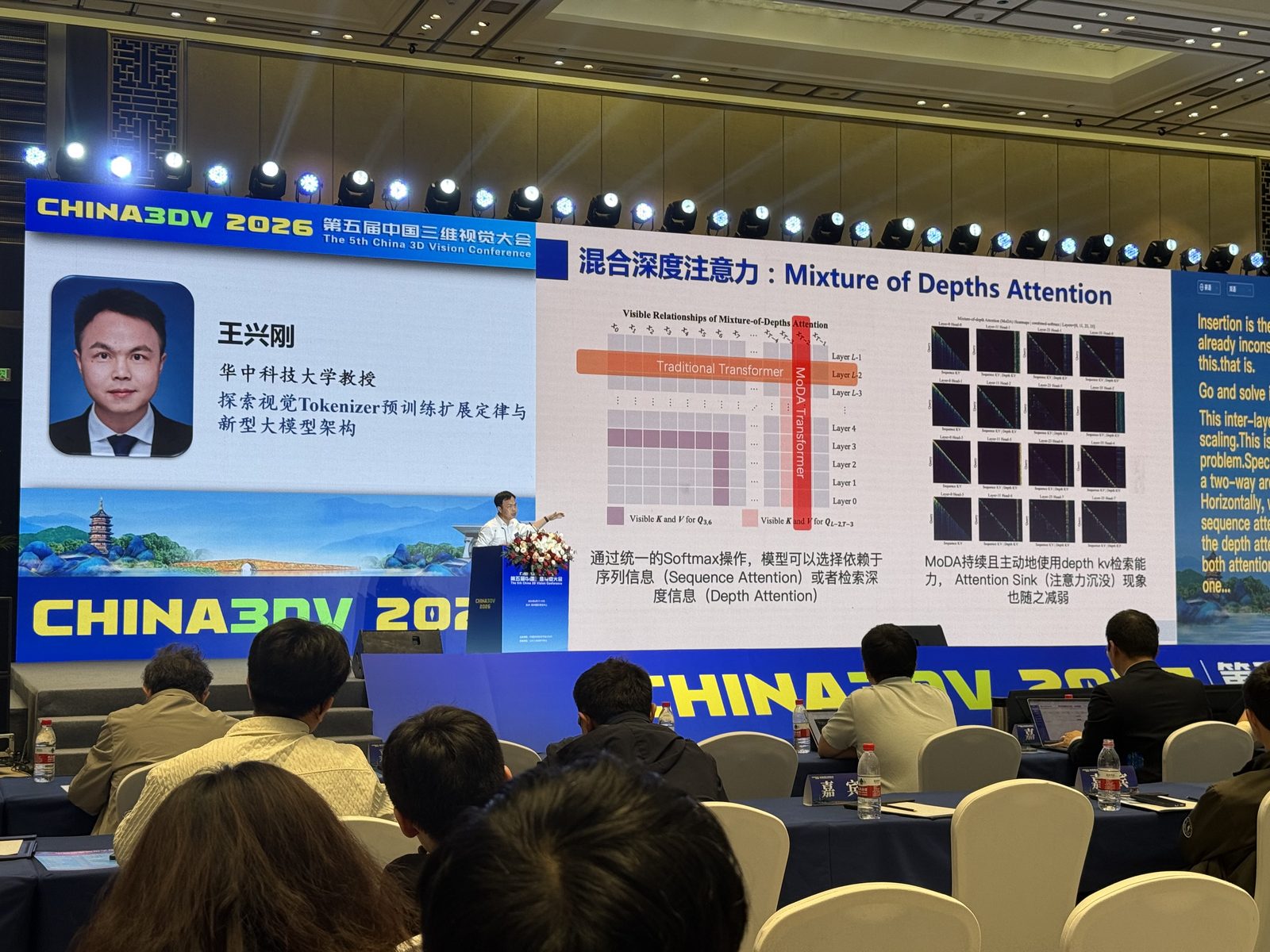
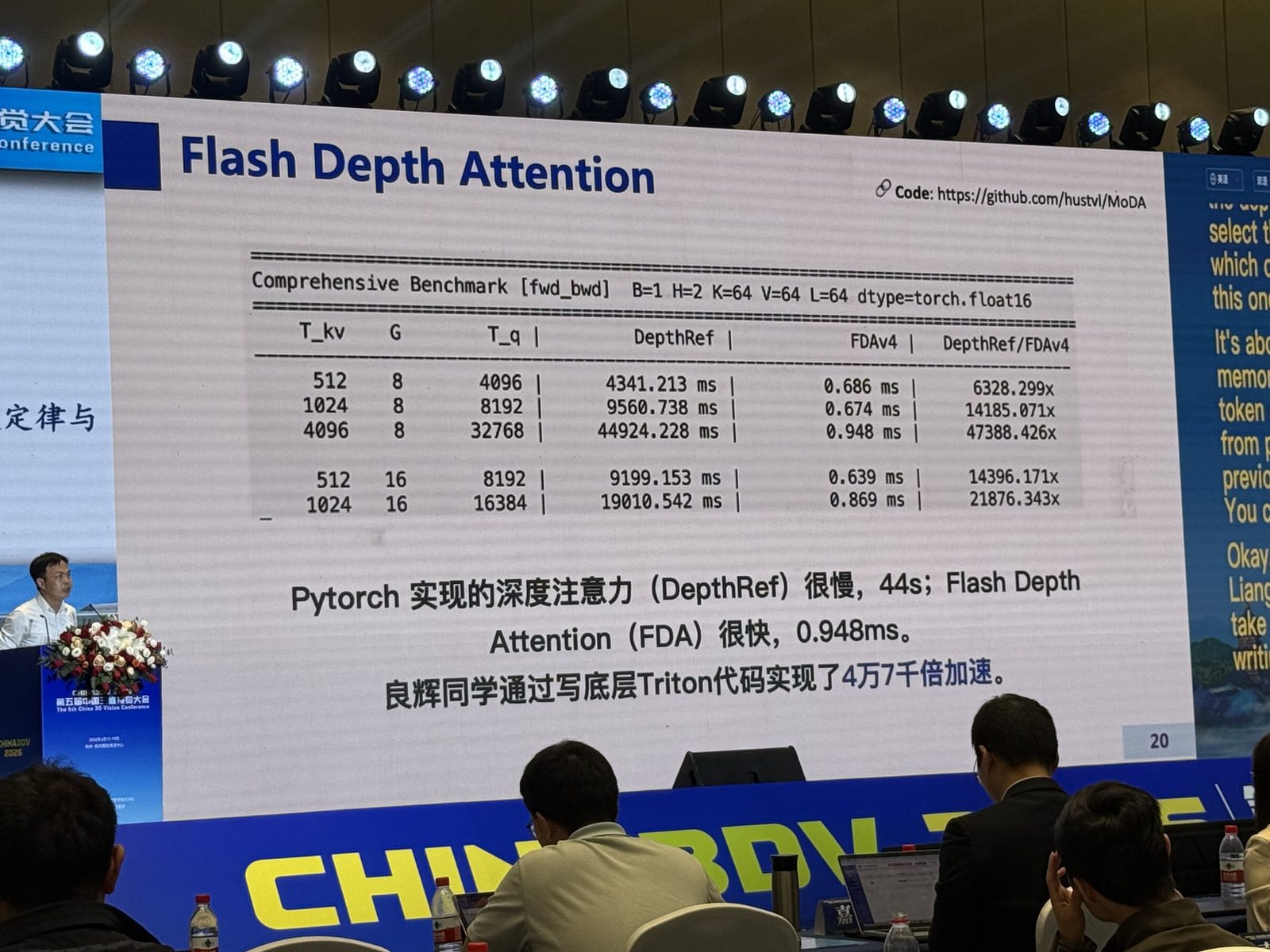
后半段则明显转到架构。slide 上的 Mixture of Depths Attention (MoDA) 讲得很具体:传统 transformer 只能看当前层的 sequence attention,而深度扩展后浅层信息会被逐渐洗掉;如果允许注意力头访问前几层的 depth memory,就有机会缓解这种信息稀释。换句话说,这场报告关注的是:视觉 tokenizer 和大模型不只是“换个更大的编码器”这么简单,而是要重新理解 representation、depth scaling 和 architecture 之间的关系。
Mixture-of-Depths Attention:这场里“混合深度注意力 / 解决 Attention Sink”最直接的对应。
走向多模态原生统一:前景与挑战









袁粒 袁粒这场可以概括成一句非常硬的判断:无多模态原生统一,就没有世界模型。 他一开场就用一个很直观的例子铺垫这个判断:GPT 数不清手指,Gemini3 却可以,这不是简单 benchmark 胜负,而是在提示“单模态 LLM 已接近极限,多模态才是未来,多模态 Scaling Law 才刚开始”。所以这场报告真正关心的不是某个当前模型,而是“什么叫原生多模态统一”。
他给出的定义也比较严格。第一是输入输出原生:不同模态能在同一个 backbone 中同时输入输出;第二是融合模态原生:不同模态在 backbone 中被同等对待,允许前后有 codec,但同一模态只能有同一套 codec。顺着这个定义,挑战也很清楚:生成方式不同、视觉编码器还没统一、生成和理解任务无法统一、模态冲突本质上是梯度冲突。报告里把这条线进一步落到自家工作图谱:统一多模态大模型(理解+生成)连接到具身大模型、科学智能 AI4S 和世界模型,而 Helios 则被作为一种原生实时架构、自回归、长时间视频生成进一步通向 3D/4D 生成的例子。
Helios:是这场关于“原生实时架构 / 自回归 / 长视频 -> 3D/4D”的直接代表。
面向长序列建模的基础模型架构


黄高 黄高这场比较短,但信息密度很高。低维度 Agent Tokens 和 QKV -> QAKV 对应 slide 上的 Agent Attention。它的核心思想是:长序列建模不一定只能靠更长的 KV cache 去硬扛,也可以引入一组更紧凑的 agent token,先聚合上下文,再广播给原始序列,从而在不完全牺牲表达能力的前提下压缩长上下文的计算量。
另一张 slide 讲的是 Compression by Learning / Test-time Training (TTT)。这和后面的 QA 能很好接上:面对多模态统一和长序列建模,到底应该做极简扩展,还是做架构重构?会场讨论里的倾向是,AR Transformer 和 Diffusion Transformer 虽然都在统一不同模态,但建模方式并不一样,一个更像 model,一个更像 modeling,因此 ART 的架构大概率还是要重构。黄高这场的价值正在于,它把这种“重构”具体化成了对 attention、memory bank、agent token 和上下文压缩机制的重新设计。
QA
下午的 QA 把当天几场的共识说透了:多模态统一不是简单把模态拼起来,而是要回答“怎样才算 auto-regressive 地统一”。会场里反复出现的几个词也很值得记下来:memory bank、真正的 MoE Hinton 从音频来、完美 3D/4D Tokenizer。这些话听起来像散点,但合在一起就是一个共同判断:如果理解为了对齐不断丢像素信息,而生成又需要像素级细节,那么割裂的模型最终很难走向具身大脑;因此无论是 tokenizer、attention、memory 还是架构本身,后面大概率都还要继续重做。