3D Reconstruction 阅读笔记
从 CroCo、DUSt3R、VGGT 到 CUT3R 的三维重建论文阅读笔记。
寒假阅读了 3D Reconstruction 的一些文章,在这里写下笔记。 有问题欢迎评论。 欢迎来仓库玩,点个 Star:
MVS Task Definition
- 多视角立体(Multiview stereo),但采用一种非优化式(optimization-style free)的自由形式
- 输入:视频序列,或一组多视角图像(bag of multiview images)
- 输出:
- 每一帧的相机位姿(平移 t、旋转 R)(也就是一个 SLAM 问题)
- 每个像素对应的 3D 点图(3D point map)
- 通常默认使用针孔相机模型(pinhole model)
Traditional Pipeline
SfM/SLAM 估计相机外参,得到稀疏点云。流程可以概括:特征 - 匹配 - 多视图几何 - 最小重投影误差 - 稠密 MVS - 融合。
BA 参考:Bundle Adjustment 光束法平差 - Cheng Wei’s Blog
CroCo
CroCo: Self-Supervised Pre-training for 3D Vision Tasks by Cross-View Completion 论文标题:CroCo:通过跨视角补全实现三维视觉任务的自监督预训练 Time: 2023.1
目标:把“预训练擅长语义、下游需要几何”的落差补上,让同一套 ViT 表征更适配深度、匹配、光流、位姿这类 3D/几何任务。
背景:自监督(MoCo、BYOL、SwAV、DINO等)更偏向全局语义和实例不变性,提升了分类、检测,但是对每个 patch 的几何关系帮助有限。DINO 在 ImageNet 线性评估强,MIM 在 dense 任务更好,但对几何仍有缺口。
单图补全没有其他信息可以依赖,通常需要依赖语意先验,而 CroCo 引入了第二个视角,模型被迫掌握真正几何关系。
方法: 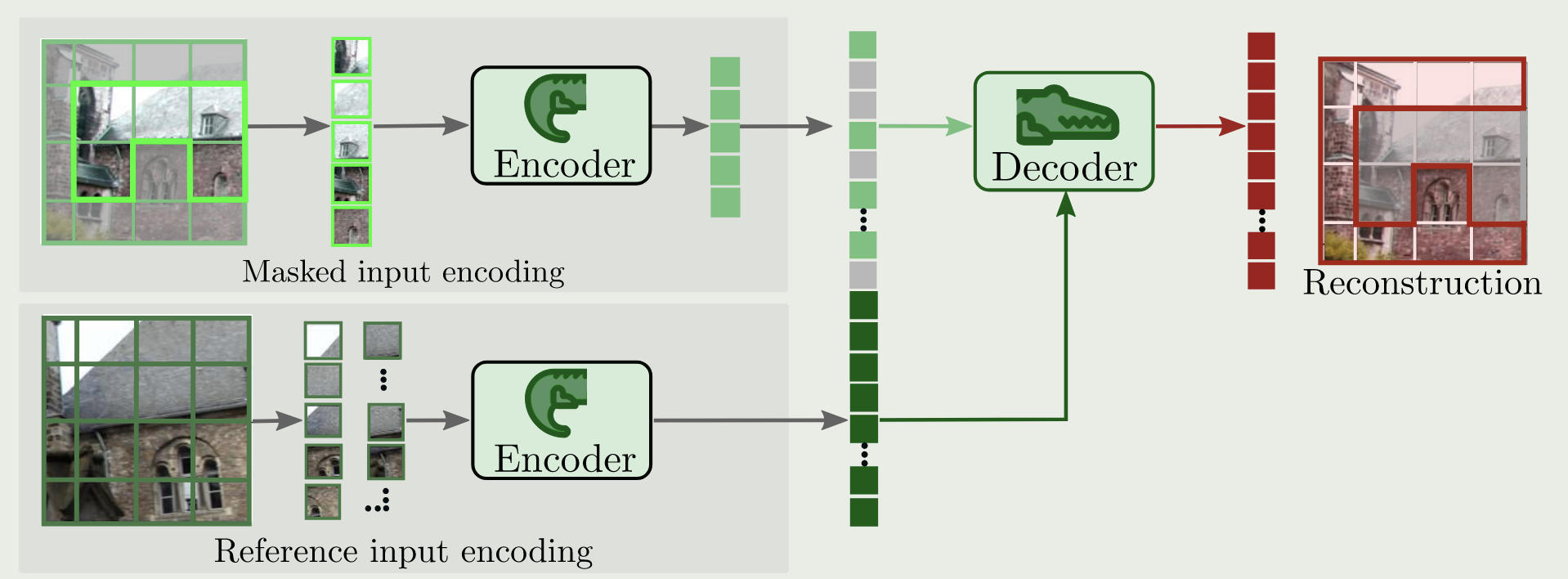
- 输入:一对同场景不同视角的图像,对第一张图做随机 mask,90%左右。
- 编码:用同一个 ViT 编码器处理两张图的 tokens,Siamese ViT。
- 解码:Decoder 输入第一张图的编码 + n 个可学习的 mask token,并且条件化第二张图的编码 token,重建第一张图的 patch。
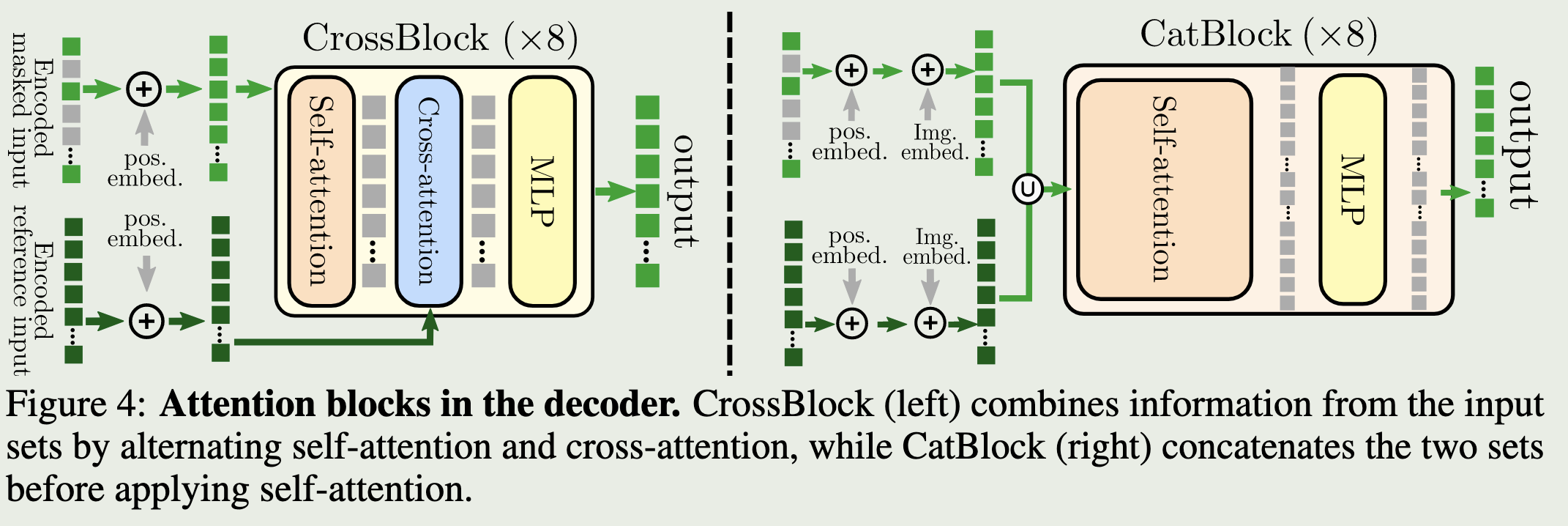 两种结构,CrossBlock 先对 view1 token 做 self-attn,再用 cross-attn 让 view1 token 去看 view2 token。CatBlock 将两个视角 token 拼接起来做 self-attn,最后取 view1 的 token 去预测。
两种结构,CrossBlock 先对 view1 token 做 self-attn,再用 cross-attn 让 view1 token 去看 view2 token。CatBlock 将两个视角 token 拼接起来做 self-attn,最后取 view1 的 token 去预测。 - 使用:单图深度估计:保留 Encoder,在上面接一个预测头。双目任务:保留 Encoder + Decoder. CroCo 核心贡献:做了 cross-view completion。用 Transformer decoder 将多视角信息注入到原图 token,再做 patch 回归。训练数据选择上,使用不同视角可以让模型学到空间关系,以适配下游任务。
Dust3r - Dense and Unconstrained Stereo 3D Reconstruction
DUSt3R: Geometric 3D Vision Made Easy Time: 2024.12
从 CroCo 到 DUSt3R-
背景:MVS 问题首先需要估计相机的内参和外参,但是传统 pipeline 又臭又长。既然 CroCo 已经被迫学到几何关系,那不妨让他直接输出 3D 坐标。  DUSt3R 抛弃了深度图,直接预测 Pointmap,$X \in \mathbb{R}^{H \times W \times 3}$. 为了做到预测 pointmap,DUSt3R 几乎原封不动照搬了 CroCo,同样使用了 Siamese ViT Encoder,让编码器拥有几何对齐能力;然后使用 self-attn 和 cross-attn 训练 Decoder。然后取出 3D Point Head 和 Confidence Head,即坐标和置信度,输出内容为 $(H, W, 3) MATHINLINE3ENDMATH (H, W, 1)$.
DUSt3R 抛弃了深度图,直接预测 Pointmap,$X \in \mathbb{R}^{H \times W \times 3}$. 为了做到预测 pointmap,DUSt3R 几乎原封不动照搬了 CroCo,同样使用了 Siamese ViT Encoder,让编码器拥有几何对齐能力;然后使用 self-attn 和 cross-attn 训练 Decoder。然后取出 3D Point Head 和 Confidence Head,即坐标和置信度,输出内容为 $(H, W, 3) MATHINLINE3ENDMATH (H, W, 1)$. 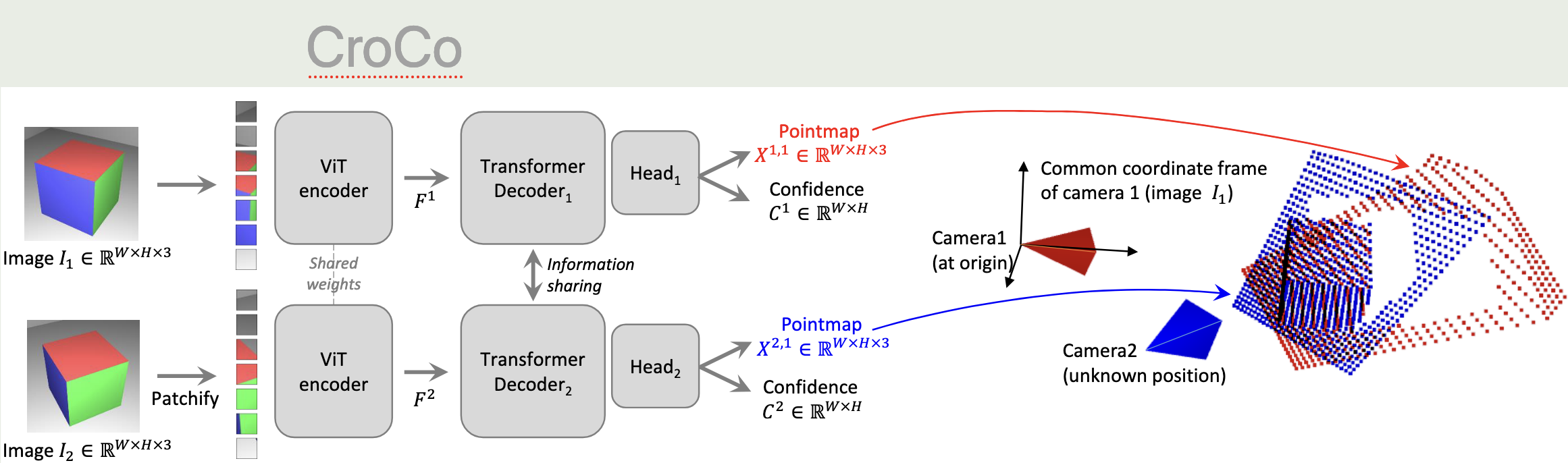 现在有了空间中的对应关系了,在设置损失函数的时候,只需要比对预测的 3D 坐标 和 真实的 3D 坐标。在尺度模糊的情况下,只需保证重建后模型的样子是一样的,所以 DUSt3R 引入了尺度不变的 3D 距离损失:$\mathcal{L}_{conf} = \sum_{i} C_i \cdot \left\| \frac{1}{z} X_i - \frac{1}{z^*} X^*_i \right\| - \alpha \log C_i$ .
现在有了空间中的对应关系了,在设置损失函数的时候,只需要比对预测的 3D 坐标 和 真实的 3D 坐标。在尺度模糊的情况下,只需保证重建后模型的样子是一样的,所以 DUSt3R 引入了尺度不变的 3D 距离损失:$\mathcal{L}_{conf} = \sum_{i} C_i \cdot \left\| \frac{1}{z} X_i - \frac{1}{z^*} X^*_i \right\| - \alpha \log C_i$ .
关于多图的应用,DUSt3R 设计了一种策略:Global Alignment。
- 先构建一个连通图 $G(V,E)$ :每张图是 node,edge 是共享的视觉内容。要么用 image retrieval,要么把所有图片过一遍网络去找 edge。
- 然后对每条边跑 DUSt3R,会拥有四个输出:$X_{n,e} , X_{m,e}, C_{n,e},C_{m,e}$ .
- 然后跑全局变量,每条边都会获得刚体位姿 $P_e \in \mathbb{R}^{3\times 4}$ 和正尺度 $\sigma_e>0$ ,分别控制位置和大小。
- 然后就比较显然了,$\chi^* = \arg \min_{\chi, P, \sigma} \sum_{e \in \mathcal{E}} \sum_{v \in e} \sum_{i=1}^{HW} C_i^{v,e} \|\chi_i^v - \sigma_e P_e X_i^{v,e}\|.$
- 避免尺度坍缩,设置约束 $\prod_{e}\sigma_e = 1$.
VGGT - Visual Geometry Grounded Transformer
Time: 2025.3
MASt3R 补全了 DUSt3R 在特征匹配和绝对物理尺度上的拼图,但是他们都是双目模型,每次只能看两张图,而 Global Alignment 这块太麻烦了。
来到了 feed-forward 网络,一次性输出相机参数、点图、深度图、3D 点轨迹。
- $g_i \in \mathbb{R}^9$ 相机参数,$g = [q, t, f]$,4维旋转 $q$,3维平移向量 $t$ 和 2 维的视场角 $f$。
- $D_i \in \mathbb{R}^{H \times W}$ 深度图
- $P_i \in \mathbb{R}^{3 \times H \times W}$ 点图
- $T_i \in \mathbb{R}^{C \times H \times W}$ 追踪特征
来看一下 VGGT 的架构。首先通过 DINOv2 提取特征,将图片切成 token。在每张图的 tokens 里额外塞入一个 Camera Token 和四个 Register Tokens。Camera Token 代表整张图视角,用于预测相机位姿,Register Token 用来吸收图片中没有用的背景信息,防止干扰几何计算。
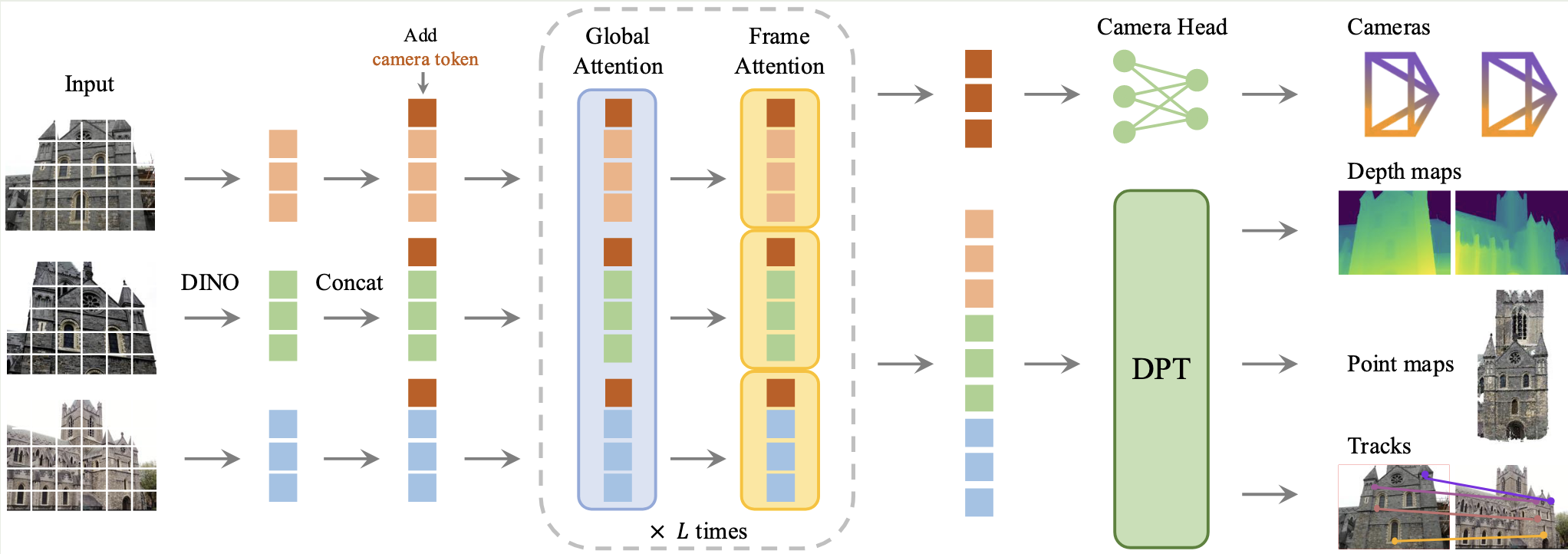
为了防止 self-attn 的复杂度太高,VGGT 用了 Frame-wise-attn:Tokens 先只和自己图中其他token交流,理解单张图的局部几何和语义;Global-attn:跨越所有图片,让同一场景下的 token 寻找匹配关系,堆叠 24 层。输入序列中,第一张图片就是世界的中心,第一张图的 Camera Token 会被赋予一套特殊的权重,之后的图片都会对齐到第一张图。
分析一下复杂度,假设现在一共有 $N$ 张图片,每张图片被切成 $K$ 个 tokens,DUSt3R 的 Attention 层复杂度是 $O(N^2 \cdot K^2)$,MLP 层复杂度是 $O(N^2 \cdot K)$. 由于图片配对的机制,同一张图片的同一个 token 在 MLP 层中会被计算 $N$ 次,造成大量算力浪费。而 VGGT 只做一次前向传播,将所有 Token 拼成一个长序列,总长度是 $N \times K$,一共 $L$ 层,一半是 F-attn 一半是 G-attn。F-attn 的复杂度是 $O(N \cdot K^2)$,G-attn 的复杂度是 $O(N^2 \cdot K^2)$,但是 MLP 的总复杂度是 $O(N \cdot K)$。要注意这里 G-attn 的复杂度相比 DUSt3R 会减少一半。
在输出端,对应每张图藏进去的 5 个额外的 tokens,VGGT 设计了预测头。 在送入注意力网络之前,除了图像的 Tokens $t^I_i$,网络还给每一帧塞入了一个相机 Token $t^g_i \in \mathbb{R}^{1 \times C'}$ 和四个寄存器 Tokens $t^R_i \in \mathbb{R}^{4 \times C'}$。 刚才提到的第一帧为世界中心,VGGT 为这一帧设定了可学习参数 $\bar{t}^g$ 和 $\bar{t}^R$ 。相机参数 $g_1$ 会被强制为旋转 $q_{1} = [0,0,0,1]$,平移设为 $t_{1}=[0,0,0]$。
- 相机预测头 拿输出的相机 Token $\hat{t}^g_i$ 再过 4 层额外的自注意力层,最后接一个线性层,直接回归出相机的参数 $\hat{g}_i$。
- 稠密预测头 用了一个叫 DPT 的东西,DPT 就是一个 ViT 的 Decoder,DPT 从 ViT 的四个不同深度提取 Tokens,经过特殊 Token 处理、重塑二维网络、重采样对齐的工作,将 Transformer 的输出转换成 2D 特征,而且是不同尺度的四组。最后再经过上采样、融合、特征细化得到特征图,可以通过一个简单的输出头(例如卷积),直接获取深度值或者 3D 坐标。VGGT 在输出头这里是用了并行的 $3 \times 3$ 卷积层来直接映射出所需向量:深度图 $D_i$ ,点图 $P_i$ ,不确定性图 $\Sigma^D_i \in \mathbb{R}^{H \times W}_+$, $\Sigma^P_i \in \mathbb{R}^{H \times W}_+$ ,Tracking 特征 $T_i$。
- Tracking 用了 CoTracker2 作为追踪模块,直接用刚才 DPT 的特征图 $T_{i}$ 进行特征采样、相关性构建、Self-attn 得到最终 2D 点坐标。

讲完这部分,就可以开始训练了。VGGT 采用 E2E 的训练模式,总损失是相机、深度、点图和追踪四个损失的加权和:$\mathcal{L} = \mathcal{L}_{camera} + \mathcal{L}_{depth} + \mathcal{L}_{pmap} + \lambda \mathcal{L}_{track}$ ,相机损失为 Huber $\mathcal{L}_{camera} = \sum_{i=1}^N \| \hat{g}_i - g_i \|_\epsilon$,深度损失 $\mathcal{L}_{depth} = \sum_{i=1}^N \left\| \Sigma^D_i \odot (\hat{D}_i - D_i) \right\| + \left\| \Sigma^D_i \odot (\nabla \hat{D}_i - \nabla D_i) \right\| - \alpha \log \Sigma^D_i$ ,点图损失和深度损失一样,追踪损失直接计算距离+二元交叉熵判断是否可见, $\lambda = 0.05$。
DINO
DETR with Improved DeNoising anchOr boxes 2022
之前 VGGT 似乎使用了 DINOv2,这条路线应该也比较重要,正好最近看到了 DINOv3,现在就来梳理一下。
DINOv1 使用无监督学习和 ViT,模型在没有标注的情况下就涌现出语义分割能力,并且特征具有极强的聚类属性。DINOv2 在 v1 的基础上进行了扩建,引入了掩码图像建模增强局部特征,还构建了一个精心清洗的数据集(LVD-142M),目标是训练出一个百搭的模型,不需要微调就能在各种下游任务拿到顶尖结果。DINOv3 则继续 scale,研究人员发现,随着 scaling,模型提取局部 dense features 的能力会逐渐退化,所以他们引入了 Gram Anchoring,用早期阶段特征矩阵的分布来约束后期的训练,成功解决特征崩溃的问题。
DINOv1
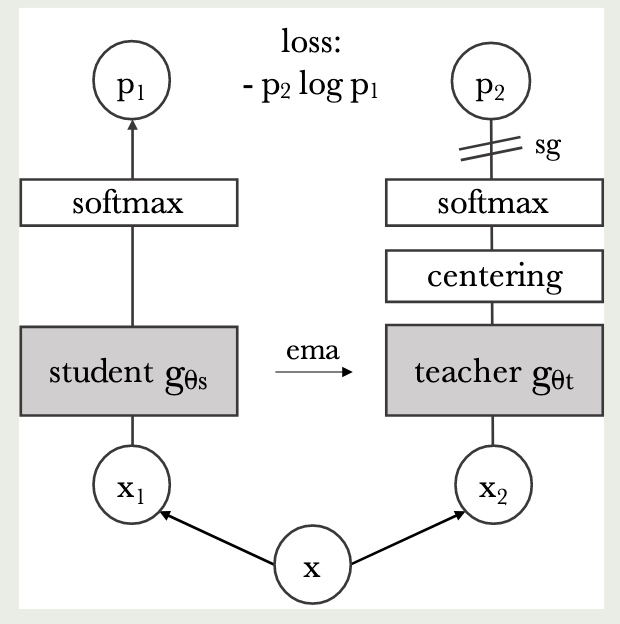
DINO 使用了无标签知识蒸馏框架。有两个网络,一个是 Student $g_{\theta_{s}}$ 另一个是 Teacher $g_{\theta_{t}}$ 。这两个网络的架构一模一样,但是参数不同。给定一张图片,模型会输出一个 $K$ 维的概率分布,通过 Softmax 和温度 $\tau$ 计算:$P_s(x)^{(i)} = \large{\frac{\exp(g_{\theta_s}(x)^{(i)}/\tau_s)}{\sum_{k=1}^K \exp(g_{\theta_s}(x)^{(k)}/\tau_s)}}$ ,老师网络同理。
学生的目标是尽量模仿老师的输出:$\min_{\theta_s} H(P_t(x), P_s(x))$.
为了让模型学到真东西,DINO 设计了 Multi-crop 的策略。对于同一张图片 $x$,裁剪出两张包含大部分区域的全局视图 $x_1^g, x_2^g$,以及多张包含局部的集合 $V$。只有全局视图会输入给老师网络,而所有的视图都会输入给学生网络。
模型需要通过局部去预测全局,损失函数写成:$\large{\min_{\theta_s} \sum_{x \in \{x_1^g, x_2^g\}} \sum_{x' \in V, x' \neq x} H(P_t(x), P_s(x'))}$.
那么老师的参数怎么来?老师的网络也是动态的,它会跟随学生的脚步慢慢更新。老师的参数是学生参数的指数移动平均,$\theta_t \leftarrow \lambda \theta_t + (1 - \lambda)\theta_s$。学生网络会用反向传播更新参数,而老师使用这个公式,老师网络通过这个 $\lambda$ (从0.996开始慢慢增加到1),表示这个老师网络会吸收学生网络的 $1-\lambda$ 的参数。为了防止训练崩溃,采用了「中心化」:$c \leftarrow mc + (1 - m)\frac{1}{B}\sum_{i=1}^B g_{\theta_t}(x_i)$ 和「锐化」$\tau_{t}$ 。中心化就是防止模型的某个维度被过度激活,锐化让模型做出非黑即白的判断,会让概率差距非常大,从而实现类似 clustering 的效果。
DINOv2
从 DINOv1 成功验证了 SS ViT,下一步的目标非常明确,就是进一步 Scale,让模型成为一个视觉基础模型。为了实现这个目标,DINOv2 在三个维度构建了它的逻辑闭环:数据清洗、多尺度损失函数和特征分布正则化。
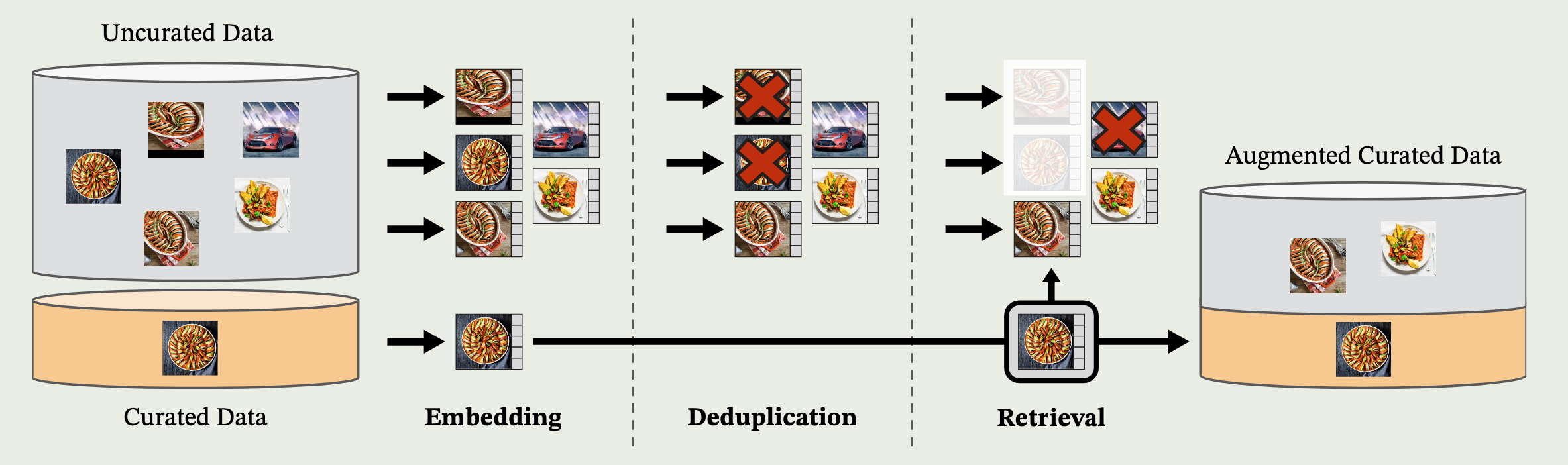
DINOv2 构建了经由去重,检索两步的数据清洗过程,筛选的话,闲拿人工筛选过的数据集作为种子,然后用种子的特征向量去庞大的网页图片库里把特征相近的图片捞出来。于是数据从 12 亿变成了 1.42 亿,也就是 LVD-142M。
损失函数方面,DINOv2 依旧沿用了学生老师的架构,在此基础上,将损失函数升级成了一个覆盖全局和局部的多维体系。
- 图像级目标:和 DINOv1 情况一致,$\mathcal{L}_{DINO} = - \sum p_t \log p_s$. 这个就是全局语义理解,就是用局部预测全局。
- 斑块级目标:只有全局理解在 3D 和密集预测任务里是不够的,为了让模型精确理解像素级别的物理关系,DINOv2引入了掩码图像建模。$\mathcal{L}_{iBOT} = - \sum_{i} p_{ti} \log p_{si}$. 全局损失,负责宏观语义,这个局部损失就是细节的补全。在 CroCo 中也有这两种任务的区别,而 CroCo 做的事情是不让模型过度依赖语义,而使用细节表征去补全 mask。
当模型参数非常大、训练数据又很多的时候,特征空间会变得非常拥挤,模型有时候为了降低 loss,会将一些不相关的图挤在特征空间的同一个角落里。DINOv2 引入了 KoLeo 正则化项,$\mathcal{L}_{koleo} = - \frac{1}{n} \sum_{i=1}^n \log(d_{n, i})$ 。这里的 $d_{n, i}$ 表示在一个Batch中,第 $i$ 个特征向量到离它最近的另一个特征向量之间的距离。
我们在损失函数里加入这个距离的负对数。要让损失最小,模型就必须让 $d_{n, i}$ 尽可能大。 所以这会让特征空间分布出奇得均衡,让 DINOv2 的结果可以直接被拿去做检索。
Cut3R
2025.01 维持一个 global state - which is a latent vector with 768 tokens. 新来一张图片和这个 global state 做 cross attention。
人类观察世界是一个不断累积经验的过程。进入一个新房间,我们只需瞥一眼就能推断出大概布局,随着我们走动看到更多角落,脑海中的3D场景模型会持续完善。现有的3D重建系统大多每次都要==从零开始计算==(如传统的SfM或NeRF),遇到输入图像稀疏或视角变化剧烈的情况就容易失效。近期的学习型方法DUSt3R虽然引入了强大的几何先验,能够仅靠图像对输出3D点云,处理多视图时需要极耗时的 Global Alignment,无法满足流式图像的在线处理需求。
基于以上痛点,作者提出了一个统一的在线3D感知框架 CUT3R。它接收没有任何相机参数的流式图像输入,利用一个带有记忆属性的持续更新状态(persistent state),在线为每一帧预测绝对尺度下的密集点云(pointmaps)和相机位姿。
这个 persistent state 包含了 768 个 token,每个 token 768个维度。两个关键的操作是:state-update & state-readout. 图像先被 ViT 编码,变成 $F_{t}$ 。 新来的图片都会与 persistent state $s_i$ 交互,先进行 update,用新来的知识更新 state,然后再 readout,获取之前的记忆。这是一个双向的操作,每次交互会使用两个 interconnected transformer decoder,互相做交叉注意力,于是有了以下公式:
- 在线处理:记忆从过去传到现在,state-update。
- 看过去上下文:state-readout,获得过去上下文信息,预测当前帧。
- 全局相机 token:z。 这个有点像 RNN 中的 hidden-state 更新,$h_t=f(h_{t-1},x_t).$ ,CUT3R 将这个公式 transformer 化、token 化,但是核心思想是 $\text{旧记忆} + \text{当前输入}\;\longrightarrow\;\text{新记忆} + \text{当前预测所需表征}.$
然后就可以根据 $F_{t}'$ 和 $z_{t}'$ 解析出 explicit 3D representation,其中 $H_{self}$ 和 $H_{world}$ 是 DPT 预测头,$H_{pose}$ 则是一个 MLP 网络。
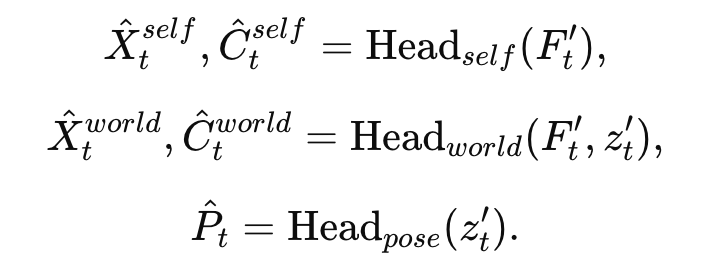
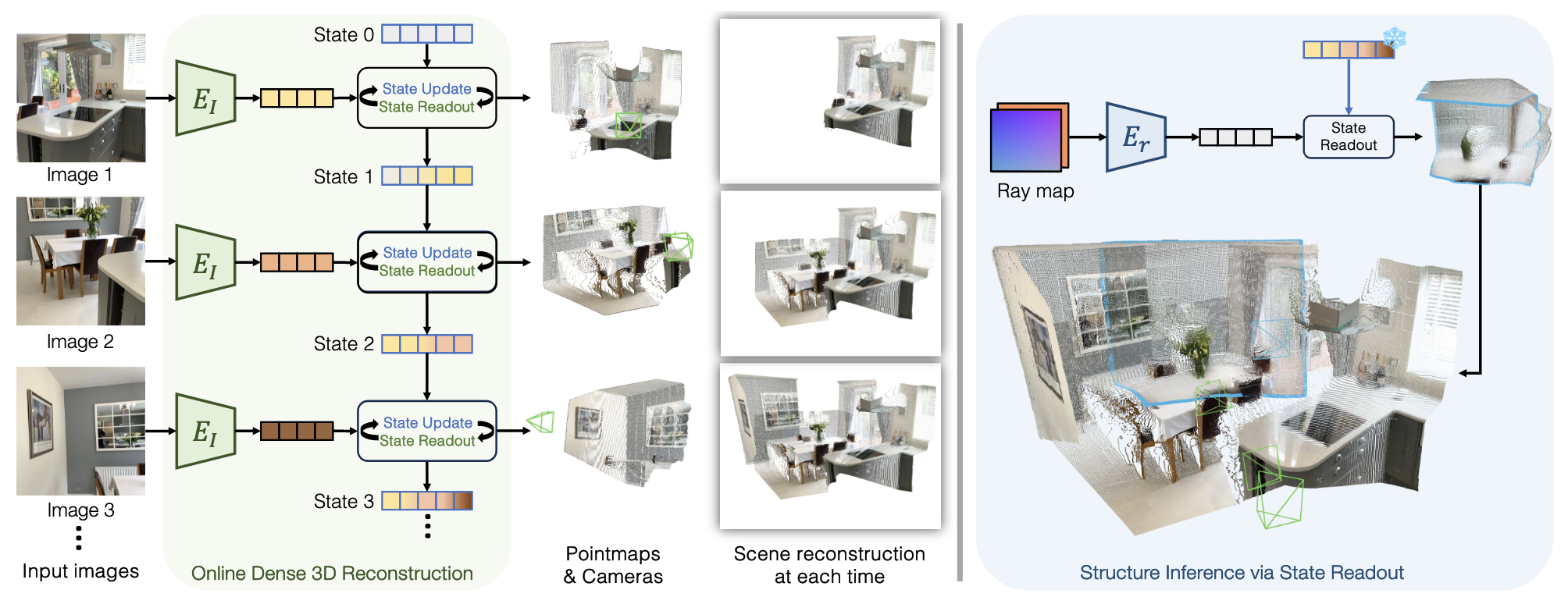
这里作者不仅解析了 self 点云,也解析了 world 点云,作者发现,这种冗余不仅让训练更加稳定,得到监督,还让只有 pose 或者只有 depth 的数据集发挥作用,可以使用更多数据集进行训练,静态动态、室内室外都可以适配。
在处理完这些输入数据之后,作者设计了虚拟相机 state query。先把相机外参用 encoder 编码,成为 $F_r$,然后丢到 state 里面只读不写,$\hat I_r=\mathrm{Head}_{color}(F'_r).$ ,于是就获得了一个全新的场景。
训练目标这一块,分别设计成:$L_{conf}=\sum_{(\hat x,c)\in(\hat X,C)}\left(c\cdot \left\|\frac{\hat x}{\hat s}-\frac{x}{s}\right\|_2^2-\alpha \log c\right).$ 用于点图监督,$L_{pose}=\sum_{t=1}^{N}\left(\|\hat q_t-q_t\|_2+\left\|\frac{\hat \tau_t}{\hat s}-\frac{\tau_t}{s}\right\|_2^2\right),$ 用于位姿监督。训练过程中,使用了 32 个数据集,从 4-view、静态场景开始,然后加入更多动态场景和更高的分辨率,最后冻结 encoder,去做 decoder 和 heads 的训练。模型方面,image encoder 用 ViT-Large,decoder 用 ViT-Base。